Phylogenetics is the study of the evolutionary relatedness among groups of organisms. Molecular phylogenetics uses sequence data to infer these relationships for both organisms and the genes they maintain. With the large amount of publicly available sequence data, phylogenetic inference has become increasingly important in all fields of biology. In the case of natural product research, phylogenetic relationships are proving to be highly informative in terms of delineating the architecture and function of the genes involved in secondary metabolite biosynthesis.
Polyketide syntheses and non-ribosomal peptide syntheses provide model examples in which individual domain phylogenies display different predictive capacities, resolving features ranging from substrate specificity to structural motifs associated with the final metabolic product. This chapter provides examples in which phylogeny has proven effective in terms of predicting functional or structural aspects of secondary metabolism. The basics of how to build a reliable phylogenetic tree are explained along with information about programs and tools that can be used for this purpose. Furthermore, it introduces the Natural Product Domain Seeker, a recently developed Web tool that employs phylogenetic logic to classify ketosynthase and condensation domains based on established enzyme architecture and biochemical function.
HTML PDFShare this article
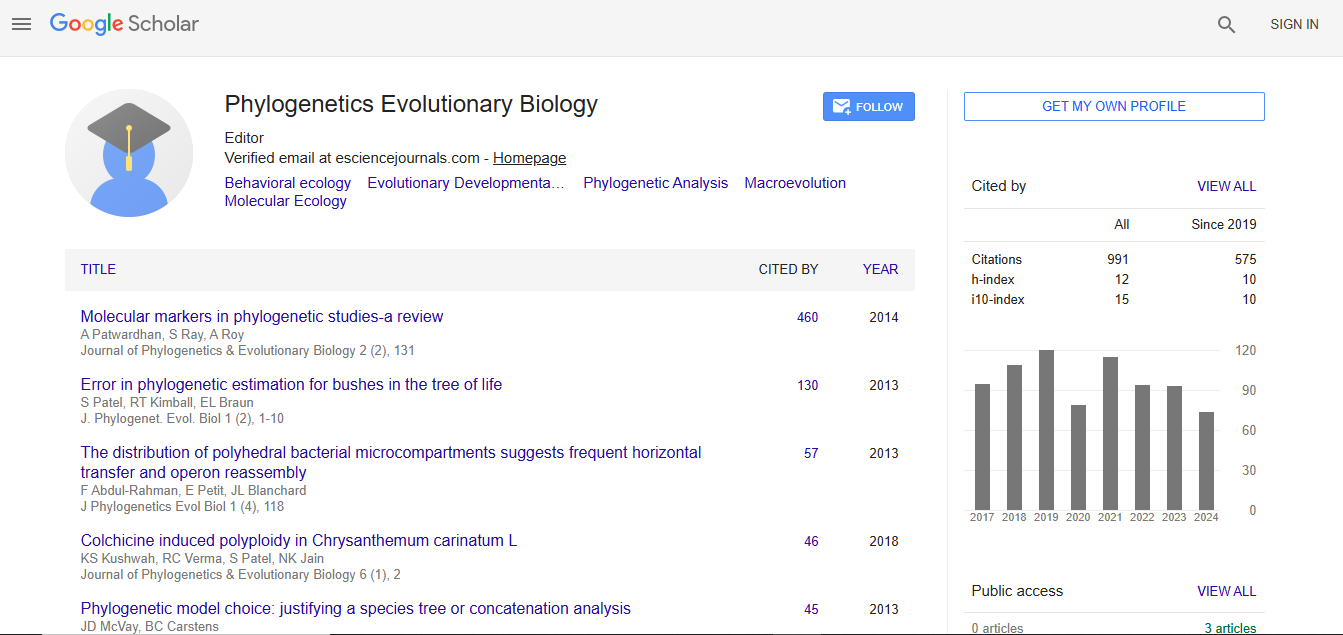
Journal of Phylogenetics & Evolutionary Biology received 911 citations as per Google Scholar report