Integrating high-dimensional data is a crucial challenge in modern computational science. As we generate and collect vast amounts of data from diverse sources, the complexity of this task increases exponentially. High-dimensional data sets are characterized by a large number of variables, which often surpass the number of observations. This disparity creates difficulties in data analysis, as traditional statistical methods tend to falter under such conditions. To address these challenges, adaptive algorithms have emerged as powerful tools, offering a computational approach to effectively integrate and analyze high-dimensional data.
Adaptive algorithms are designed to adjust their parameters and structures based on the characteristics of the data they process. This flexibility makes them particularly well-suited for handling high-dimensional data, where the relationships between variables are often complex and not easily discernible. These algorithms are capable of learning and evolving as they interact with the data, allowing for more accurate modeling and integration of high-dimensional datasets.
HTML PDFShare this article
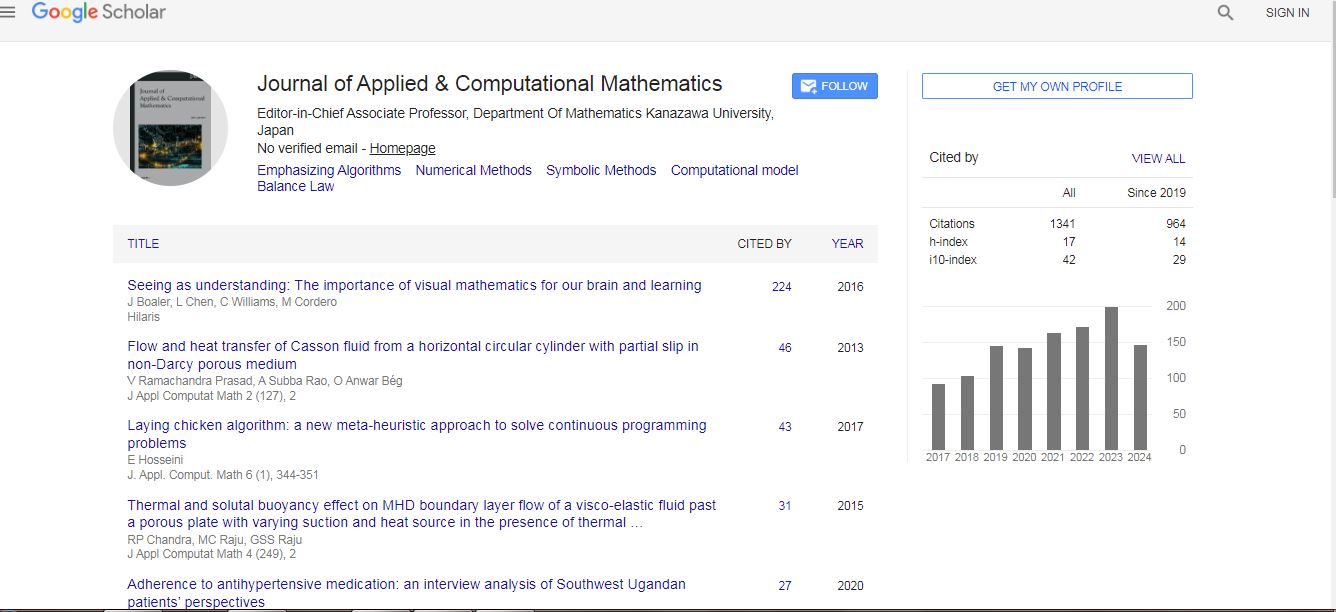
Journal of Applied & Computational Mathematics received 1282 citations as per Google Scholar report