Qing T. Zeng,Doug Redd,Guy Divita*,Samah Jarad,Cynthia Brandt,Jonathan R. Nebeker
Objective: To characterize text and sublanguage in medical records to better address challenges within Natural Language Processing (NLP) tasks such as information extraction, word sense disambiguation, information retrieval, and text summarization. The text and sublanguage analysis is needed to scale up the NLP development for large and diverse free-text clinical data sets. Design: This is a quantitative descriptive study which analyzes the text and sublanguage characteristics of a very large Veteran Affairs (VA) clinical note corpus (569 million notes) to guide the customization of natural language processing (NLP) of VA notes. Methods: We randomly sampled 100,000 notes from the top 100 most frequently appearing document types. We examined surface features and used those features to identify sublanguage groups using unsupervised clustering. Results: Using the text features we are able to characterize each of the 100 document types and identify 16 distinct sublanguage groups. The identified sublanguages reflect different clinical domains and types of encounters within the sample corpus. We also found much variance within each of the document types. Such characteristics will facilitate the tuning and crafting of NLP tools. Conclusion: Using a diverse and large sample of clinical text, we were able to show there are a relatively large number of sublanguages and variance both within and between document types. These findings will guide NLP development to create more customizable and generalizable solutions across medical domains and sublanguages.
PDFShare this article
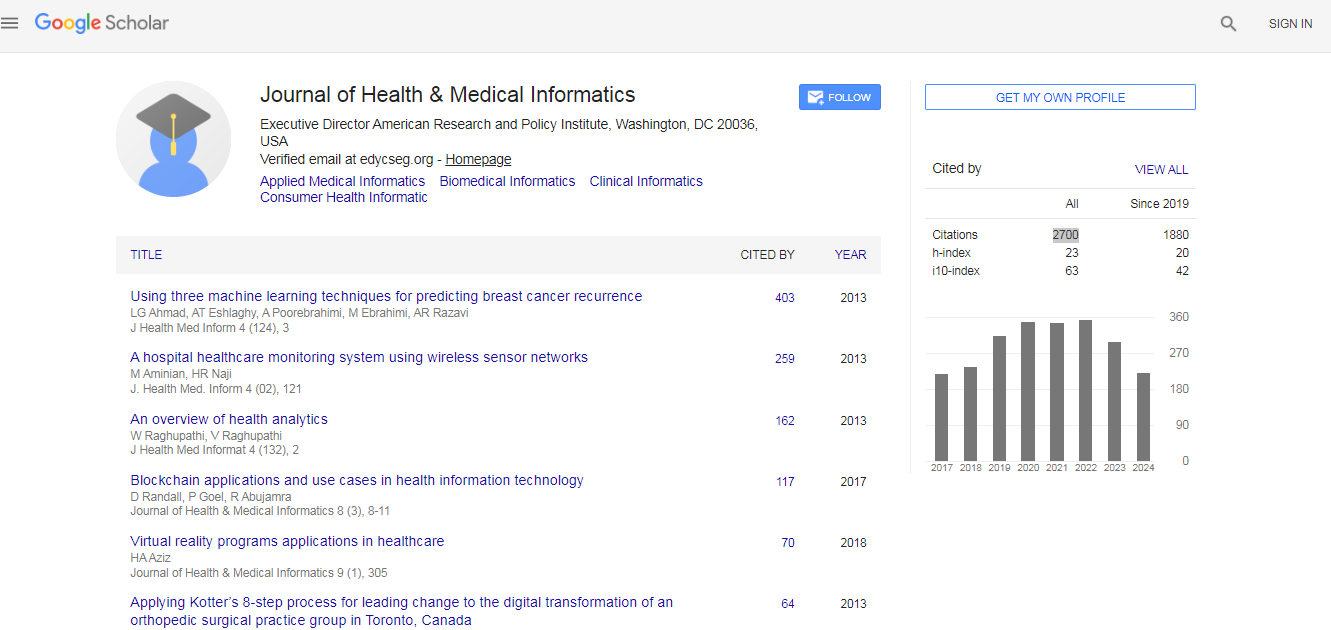
Journal of Health & Medical Informatics received 2700 citations as per Google Scholar report