Animesh Acharjee, Richard Finkers, Richard GF Visser and Chris Maliepaard
Background: In this study, we compare methods that can be used to relate a phenotypic trait of interest to an ~omics data set, where the number or variables outnumbers by far the number of samples.
Methods: We apply univariate regression and different regularized multiple regression methods: ridge regression (RR), LASSO, elastic net (EN), principal components regression (PCR), partial least squares regression (PLS), sparse partial least squares regression (SPLS), support vector regression (SVR) and random forest regression (RF). These regression methods were applied to a data set from a potato mapping population, where we predict potato flesh colour from a metabolomics data set.
Results: We compare the methods in terms of the mean square error of prediction of the trait, goodness of fit of the models, and the selection and ranking of the metabolites. In terms of the prediction error, elastic net performed better than the other methods. Different numbers of variables are selected by the methods that allow variable selection but seven variables were in common between LASSO, EN and SPLS. SPLS performed better than EN with respect to the selection of grouped correlated variables.
Conclusions: Four out of these seven variables selected by LASSO, EN, SPLS were putatively identified as carotenoid derived compounds; since the carotenoid pathway is important for flesh colour of potato, this indicates that meaningful compounds are selected. We developed a web application that can perform all the described methods, and that includes a double cross validation for optimization of the methods and for proper estimation of the prediction error.
PDFShare this article
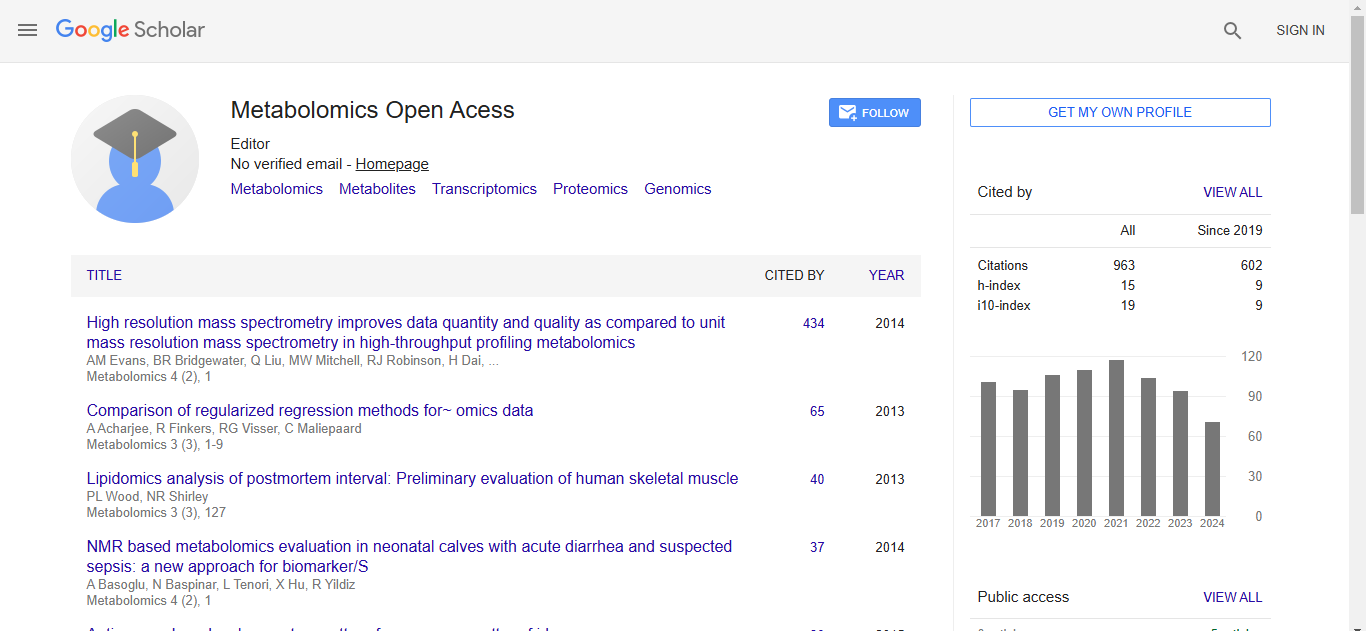
Metabolomics:Open Access received 895 citations as per Google Scholar report