Hailiang Long, Xia Wu, Zhenghao Guo, Jianhong Liu and Bin Hu
Depression is a severe mental health disorder with high societal costs. Despite its high prevalence, its diagnostic rate is very low. To assist clinicians to better diagnose depression, researchers in recent years have been looking at the problem of automatic detection of depression from speech signals. In this study, a novel multi-classifier system for depression detection in speech was developed and tested. We collected speech data in different ways, and we examined the discriminative power of different speech types (such as reading, interview, picture description, and video description). Considering that different speech types may elicit different levels of cognitive effort and provide complementary information for the classification of depression, we can utilize various speech data sets to gain a better result for depression recognition. All individual learners formed a pool of classifiers, and some individual learners with a high diversity and accuracy in the pool were selected. In the process, the kappa-error diagram helped us make decisions. Finally, a multi-classifier system with a parallel topology was built, and each individual learner in this system used different speech data types and speech features. In our experiment, a sample of 74 subjects (37 depressed patients and 37 healthy controls) was tested and a leave-one-out cross-validation scheme was used. The experiment result showed that this new approach had a higher accuracy (89.19%) than that of single classifier methods (the best is 72.97%). In addition, we also found that the overall recognition rate using interview speech was higher than those employing picture description, video description, and reading speech. Furthermore, neutral speech showed better performance than positive and negative speech.
PDFShare this article
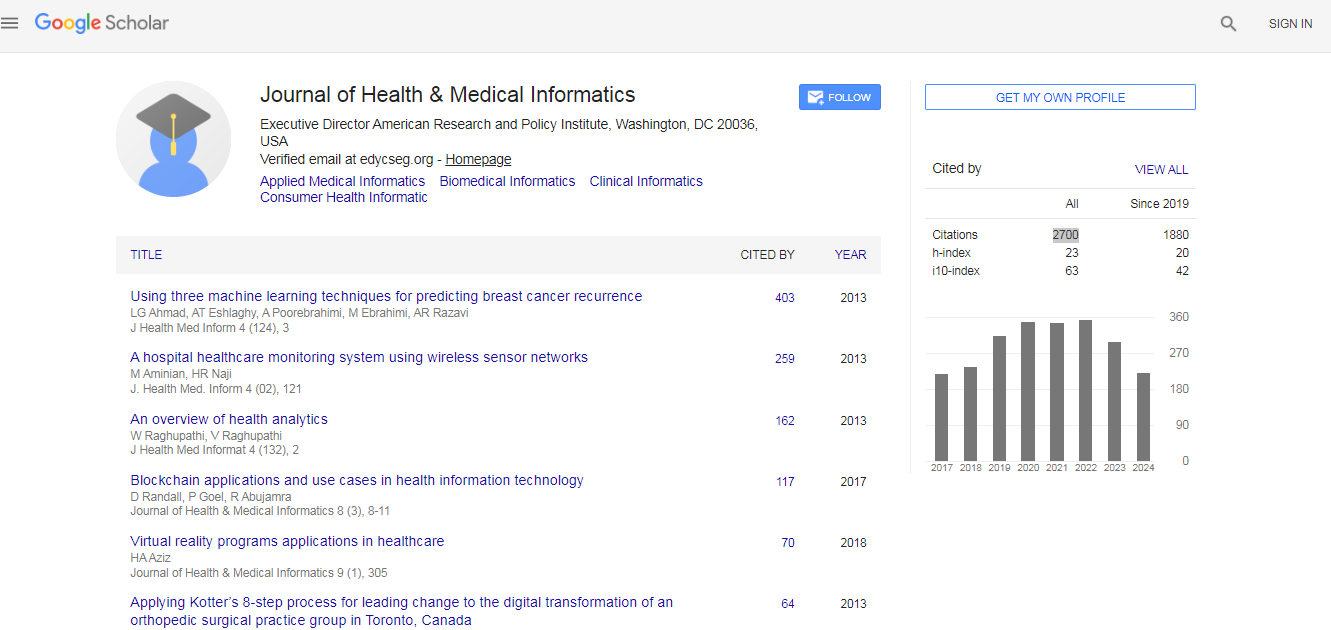
Journal of Health & Medical Informatics received 2700 citations as per Google Scholar report