Ningzhou Zeng, Guo-Qiang Zhang, Xiaojin Li and Licong Cui
Patient cohort identification across heterogeneous data sources is a challenging task, which may involve a complicated process of data loading, harmonization and querying. Most existing cohort identification tools use a relational database model implemented in SQL for storing patient data. However, SQL databases have restrictions on the maximum number of columns in a table, which necessitates the breaking down of high dimensional data into multiple tables and as a consequence affects query performance. In this paper, we developed two NoSQL-based patient cohort query systems based on an existing SQL-based system for the cross-cohort query in the National Sleep Resource Research (NSRR). We used eight NSRR datasets in our experiment to evaluate the performance of the NoSQLbased and SQL-based systems in data loading, harmonization and query. Our experiment showed that NoSQL-based approaches outperformed the SQL-based and are rather promising for developing patient cohort query systems across heterogeneous data sources.
PDFShare this article
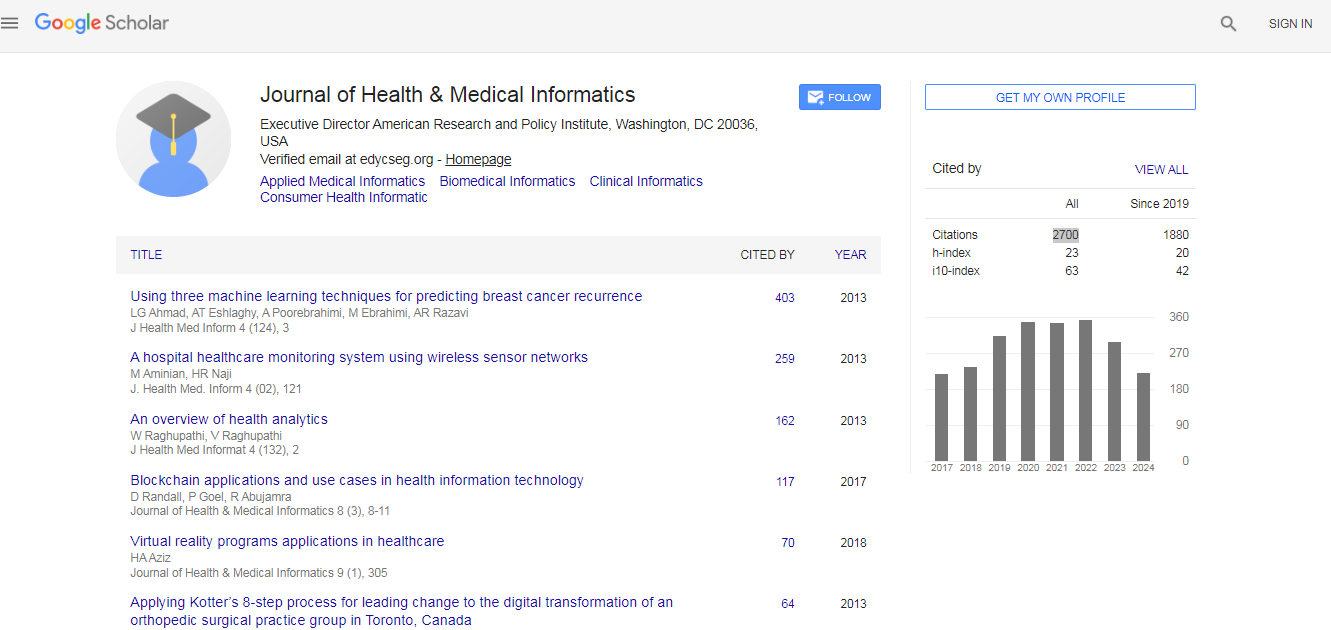
Journal of Health & Medical Informatics received 2700 citations as per Google Scholar report