Anup Som
The use of genome-scale approach in phylogenetic analysis is imperative in order to resolve evolutionary relationships over large taxon sets and deep phylogenetic divergences. But yet it is not clear what are the strengths and weaknesses of the various phylogenetic methods or which one should be preferred under genome-scale approach. In this article, the performance of five major phylogenetic methods is evaluated under genome-scale approach using biologically realistic simulated data. The following phylogenetic methods are considered; Bayesian, maximum likelihood (ML), neighbor joining (NJ), NJ maximum composite likelihood (NJ-MCL), and maximum parsimony (MP). Simulation results show that probabilistic methods (i.e., Bayesian and ML methods) are much more accurate than the NJ-MCL, MP and NJ methods. Concerning the consistency of methods, ML is consistent than other methods. This analysis shows that the NJ-MCL, MP, and NJ methods are fast (i.e., computationally efficient), but their accuracy and consistency are very poor compared to Bayesian and ML methods. On the other hand, the Bayesian method is an accurate one, but less consistent than the ML method, and it takes much longer execution time. Therefore, based on the accuracy, consistency and computational efficiency the ML method is the preferred algorithm under genome-scale approach. In addition to the methods performance, this study has investigated several important aspects of genomescale phylogeny; such as how concatenations of longest and smallest genes make effect on the method’s performance, how much datasets are needed to recover the true tree (i.e. true evolutionary history of a group of species or genes), and whether more genes or more characters are important. These are explained in the result section.
PDFShare this article
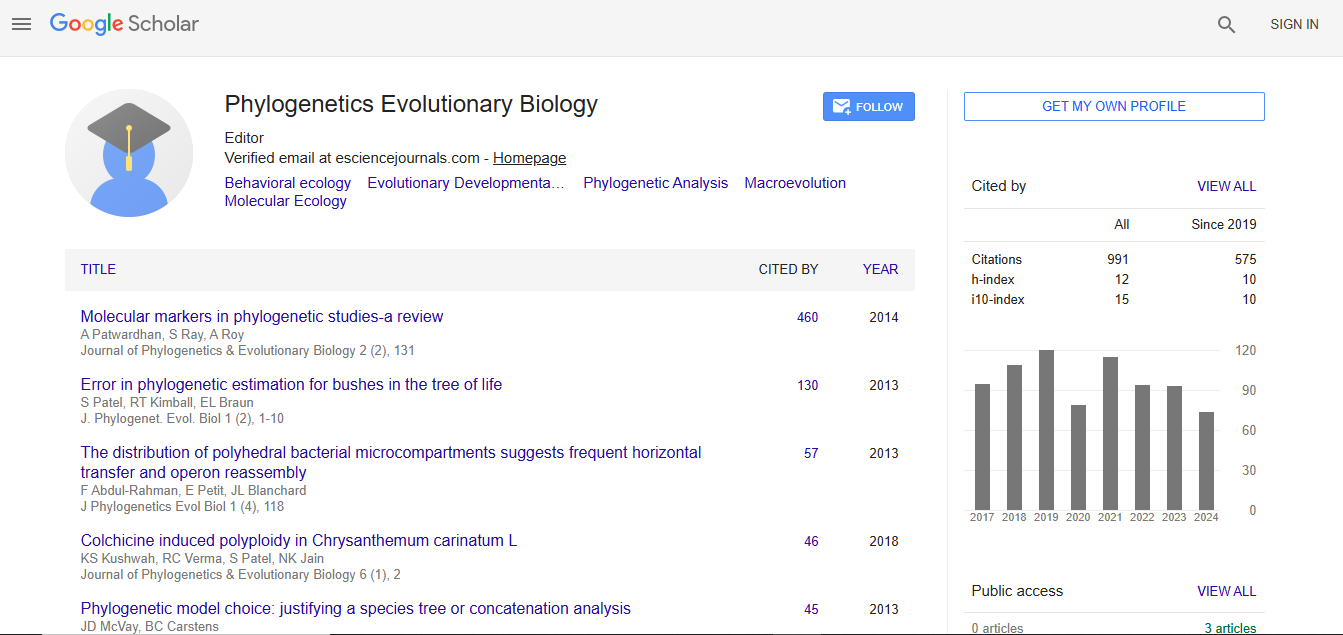
Journal of Phylogenetics & Evolutionary Biology received 911 citations as per Google Scholar report