Neda Navidi
Human / AI interaction loop training as a new approach for interactive learning with reinforcement-learning: Reinforcement-Learning (RL) in various decision-making tasks of Machine-Learning (ML) provides effective results with an agent learning from a stand-alone reward function. However, it presents unique challenges with large amounts of environment states and action spaces, as well as in the determination of rewards. This complexity, coming from high dimensionality and continuousness of the environments considered herein, calls for a large number of learning trials to learn about the environment through RL. Imitation-Learning (IL) offers a promising solution for those challenges, using a teacher’s feedback. In IL, the learning process can take advantage of human-sourced assistance and/or control over the agent and environment. In this study, we considered a human teacher, and an agent learner. The teacher takes part in the agent’s training towards dealing with the environment, tackling a specific objective, and achieving a predefined goal. Within that paradigm, however, existing IL approaches have the drawback of expecting extensive demonstration information in long-horizon problems. With this work, we propose a novel approach combining IL with different types of RL methods, namely State–action–reward–state–action (SARSA) and Proximal Policy Optimization (PPO), to take advantage of both IL and RL methods. We address how to effectively leverage the teacher’s feedback – be it direct binary or indirect detailed – for the agent learner to learn sequential decision-making policies. The results of this study on various OpenAI-Gym environments show that this algorithmic method can be incorporated with different RL-IL combinations at different respective levels, leading to significant reductions in both teacher effort and exploration costs.
PDFShare this article
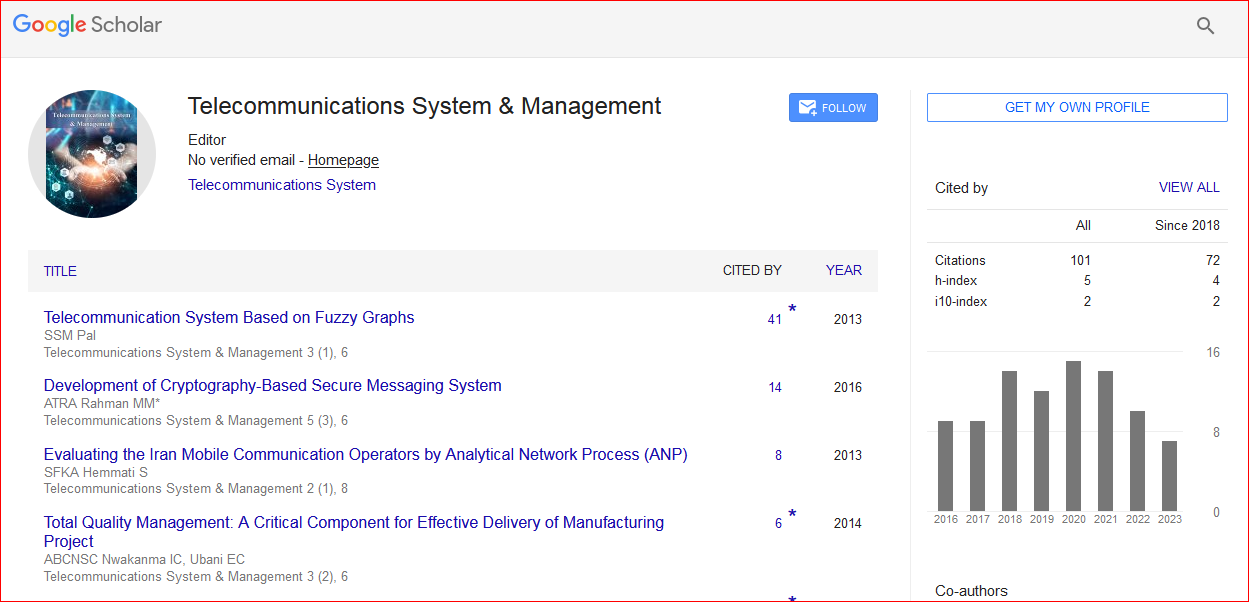
Telecommunications System & Management received 109 citations as per Google Scholar report