Katharina Glass
About 3 years ago, my boss decided that it’s time to leverage the superpowers of data. So, I was the first data scientist, a unicorn, amongst 6600 colleges at Aurubis. The primary task was to introduce, to explain, promote and establish data science skillset within the organization. Old industry, like metallurgy and mining, are not the typical examples of successful digital transformation because the related business models are extremely stable, even in the era of hyper-innovation. At least this is what some people believe, and it’s partly true, because for some branches, there is no burning platform for digitization, and hence, the change process is inert. Data science is the fundamental component of digital transformation. Our contribution to the change has a huge impact because we can extract the value from the data and generate the business value, to show people what can be done when the data is there and valid.
I learned that most valuable, essential skills to succeed in our business are not necessarily programming and statistics. We all have training on data science methods at its best. The two must have skills are resilience and communication. Whenever you start something new, you will fail. You must be and stay resilient to rise strongly. Moreover, in the business world is the ability to communicate - tell data-based stories, to visualize and to promote them is crucial. As a data scientist you can only be as good as your communications skills are, since you need to persuade others to make decisions or help to build products based on your analyses. Finally, dare to start simple. When you introduce data science in the industry, you start on the brown field. Simple use cases and projects like metrics, dashboards, reports, historical analysis help you to understand the business model and to assess where is your contribution to success of the company. This is the key to data science success, not only in the multimetal but everywhere else as well.
Commonly known by the term “big data”, Data Science is the study of the generalizable extraction of knowledge from data. It assesses the behaviour of data in a controlled, logic-led, responsive environment for deriving automated solutions and prognostic models for a given situation, problem or business objective. From Tinder to Facebook; LinkedIn to various online giants like Amazon and Google, Data science is playing a pivotal role in making the data scientist the new sought-after job in the market. Using large amounts of data for decision making has become practical now, with industries hiring qualified data scientists to handle a wide range of unprocessed data to come up with modern workable solutions catering to their respective market. Gone are the days when companies used to work on software like Excel only to analyse and store data. Even at that time, only some intelligent ventures worked with SPSS and strata
Wen Yi
Intelligence studies is a method of using modern information technology and soft science research methods to form valuable information products by collecting, selecting, evaluating and synthesizing information resources. With the advent of the era of big data, the core work of information analysis with data is facing enormous opportunities and challenges. How to make good use of big data in an effort to solve the problem of big data, optimize and improve the traditional intelligence studies methods and tools, innovation and research based on big data are the key issues that need to be studied and solved in current intelligence studies work.
Through the analysis of intelligence studies methods and common tools under the background of big data, we sort out the processes and requirements of the intelligence studies work under big data environment, design and implement a universal knowledge computing platform for intelligence studies, which enables intelligence analysts to easily use all kinds of big data analysis algorithms without writing programs (http://www.zhiyun.ac.cn). Our platform is built upon the open source big data system of Hadoop and Spark. All the data are stored in the distributed file system HDFS and data management system of Hive. All of the computational resources are managed with Yarn and each of the submitted task is scheduled with the workflow scheduler system Oozie. The core of the platform consists of three modules: data management, data calculation and data visualization.
The data management module is used to store and manage the relevant data of intelligence studies, which consists of four parts: metadata management, data connection, data integration and data management. The platform supports the import and management of multi-source heterogeneous data, including papers, patents from ISI, PubMed, etc., and also supports the data import with API of MySQL, Hive and other database systems. The platform has more than 20 kinds of data cleaning and updating rules, such as search and replace, regular cleaning, null filling, etc., and also supports users to customize and edit the cleaning rules.
The data calculation module is used to store and manage the big data analysis algorithm and intelligence analysis process, and provides a user-friendly GUI for users to create customized intelligence analysis process, and the packaged process can be submitted to the platform for calculation and obtain the calculation results of each step. In the system, a task is formulated as a directed acyclic graph (DAG) in which the source data flows into the root nodes. Each node makes operations on the data, generates new data, and sends the generated data to its descendant nodes for conducting further operations. Finally, the results flow out from the leaf nodes. The data visualization module is used to visualize the results of intelligence analysis and calculation, including more than ten kinds of visualization charts such as line chart, histogram chart, radar chart and word cloud chart.
Practice has proved that the platform can well meet the requirements of intelligence studies in various fields in the era of big data, and promote the application of data mining and knowledge discovery in the field of intelligence studies.
Zolo Kiala
The invasive Parthenium weed (Parthenium hyterophorus) adversely affects animal and human health, agricultural productivity, rural livelihoods, local and national economies, and the environment. Its fast spreading capability requires consistent monitoring for adoption of relevant mitigation approaches, potentially through remote sensing. To date, studies that have endeavoured to map the Parthenium weed have commonly used popular classification algorithms that include Support vector machines and Random forest classifiers, which do not capture the complex structural characteristics of the weed. Furthermore, determination of site or data specific algorithms, often achieved through intensive comparison of algorithms, is often laborious and time consuming. Also, selected algorithms may not be optimal on datasets collected in other sites. Hence, this study adopted the Tree-based Pipeline Optimization Tool (TPOT), an automated machine learning approach that can be used to overcome high data variability during the classification process. Using Sentinel-2 and Landsat 8 imagery to map Parthenium weed, wee compared the outcome of the TPOT to the best performing and optimized algorithm selected from sixteen classifiers on different training datasets. Results showed that the TPOT model yielded a higher overall classification accuracy (88.15%) using Sentinel-2 and 74 % using Landsat 8, accuracies that were higher than the commonly used robust classifiers. This study is the first to demonstrate the value of TPOT in mapping Parthenium weed infestations using satellite imagery. Its adoption would therefore be useful in limiting human intervention while optimising classification accuracies for mapping invasive plants. Based on these findings, we propose TPOT as an efficient method for selecting and tuning algorithms for Parthenium discrimination and monitoring, and indeed general vegetation mapping.
Tree-based Pipeline Optimization Tool (TPOT) (Olson and Moore 2016) is a novel AutoML that applies genetic programming (GP) to optimize machine learning pipelines of the sklearn python library for classification and regression problems. The following pipeline operators are implemented in TPOT: pre-processors, decomposition, feature selection, and models. During the optimization process, subsets of the ML pipelines are defined as GP primitives, which are organized as in a tree structure to form individuals. To obtain the optimal combination of processes, GP optimizes the number and order of pipeline operators, as well as each operator’s parameters (Sohn, Olson, and Moore 2017). More details on the tool can be found in (Olson and Moore 2016). An example of TPOT workflow is illustrated in Figure 2. In this study, the choice of TPOT parameters was premised on the assumption that better results are achieved with more central processing unit (CPU) time allocated (Hutter, Kotthoff, and Vanschoren 2019). Therefore, parameters such as ‘generations’, ‘population_size’ and ‘verbosity’ were set to 500, 100 and 2 respectively. Furthermore a ‘random_state’ parameter was added to the python code containing the best pipeline generated by TPOT to allow replication
The invasive Parthenium weed (Parthenium hyterophorus) adversely affects animal and human health, agricultural productivity, rural livelihoods, local and national economies, and the environment. Its fast spreading capability requires consistent monitoring for adoption of relevant mitigation approaches, potentially through remote sensing. To date, studies that have endeavoured to map the Parthenium weed have commonly used popular classification algorithms that include Support vector machines and Random forest classifiers, which do not capture the complex structural characteristics of the weed. Furthermore, determination of site or data specific algorithms, often achieved through intensive comparison of algorithms, is often laborious and time consuming. Also, selected algorithms may not be optimal on datasets collected in other sites. Hence, this study adopted the Tree-based Pipeline Optimization Tool (TPOT), an automated machine learning approach that can be used to overcome high data variability during the classification process. Using Sentinel-2 and Landsat 8 imagery to map Parthenium weed, wee compared the outcome of the TPOT to the best performing and optimized algorithm selected from sixteen classifiers on different training datasets. Results showed that the TPOT model yielded a higher overall classification accuracy (88.15%) using Sentinel-2 and 74 % using Landsat 8, accuracies that were higher than the commonly used robust classifiers. This study is the first to demonstrate the value of TPOT in mapping Parthenium weed infestations using satellite imagery. Its adoption would therefore be useful in limiting human intervention while optimising classification accuracies for mapping invasive plants. Based on these findings, we propose TPOT as an efficient method for selecting and tuning algorithms for Parthenium discrimination and monitoring, and indeed general vegetation mapping.
Tree-based Pipeline Optimization Tool (TPOT) (Olson and Moore 2016) is a novel AutoML that applies genetic programming (GP) to optimize machine learning pipelines of the sklearn python library for classification and regression problems. The following pipeline operators are implemented in TPOT: pre-processors, decomposition, feature selection, and models. During the optimization process, subsets of the ML pipelines are defined as GP primitives, which are organized as in a tree structure to form individuals. To obtain the optimal combination of processes, GP optimizes the number and order of pipeline operators, as well as each operator’s parameters (Sohn, Olson, and Moore 2017). More details on the tool can be found in (Olson and Moore 2016). An example of TPOT workflow is illustrated in Figure 2. In this study, the choice of TPOT parameters was premised on the assumption that better results are achieved with more central processing unit (CPU) time allocated (Hutter, Kotthoff, and Vanschoren 2019). Therefore, parameters such as ‘generations’, ‘population_size’ and ‘verbosity’ were set to 500, 100 and 2 respectively. Furthermore a ‘random_state’ parameter was added to the python code containing the best pipeline generated by TPOT to allow replication
Smaranya Dey, Subhadip Paul, Uddipto Dutta, Anirban Chatterjee
Forecasting in time-series data is at the core of various business decision making activities. One key characteristic of many practical time series data of different business metrics such as orders, revenue, is the presence of irregular yet moderately frequent spikes of very high intensity, called extreme observation. Forecasting such spikes accurately is crucial for various business activities such as workforce planning, financial planning, inventory planning. Traditional time series forecasting methods such as ARIMA, BSTS, are not very accurate in forecasting extreme spikes. Deep Learning techniques such as variants of LSTM tend to perform only marginally better than these traditional techniques. The underlying assumption of thin tail of data distribution is one of the primary reasons for such models to falter on forecasting extreme spikes as moderately frequent extreme spikes result in heavy tail of the distribution. On the other hand, literatures, proposing methods to forecast extreme events in time series, focused mostly on extreme events but ignored overall forecasting accuracy. We attempted to address both these problems by proposing a technique where we considered a time series signal with extreme spikes as the superposition of two independent signals - (1) a stationary time series signal without extreme spike (2) a shock signal consisting of near-zero values most of the time along with few spikes of high intensity. We modelled the above two signals independently to forecast values for the original time series signal. Experimental results show that the proposed technique outperforms existing techniques in forecasting both normal and extreme events. A tempest flood hindcast for the west shoreline of Canada was produced for the time frame 1980–2016 utilizing a 2D nonlinear barotropic Princeton Ocean Model constrained by hourly Climate Forecast System Reanalysis wind and ocean level pressing factor. Approval of the displayed storm floods utilizing tide measure records has shown that there are broad zones of the British Columbia coast where the model doesn't catch the cycles that decide the ocean level fluctuation on intraseasonal and interannual time scales. A portion of the inconsistencies are connected to enormous scope variances, for example, those emerging from significant El Niño and La Niña occasions. By applying a change in accordance with the hindcast utilizing a sea reanalysis item that consolidates enormous scope ocean level changeability and steric impacts, the difference of the mistake of the changed floods is fundamentally decreased (by up to half) contrasted with that of floods from the barotropic model. The significance of baroclinic elements and steric impacts to exact tempest flood anticipating in this waterfront area is illustrated, just like the need to consolidate decadal-scale, bowl explicit maritime inconstancy into the assessment of outrageous beach front ocean levels. The outcomes improve long haul extraordinary water level gauges and stipends for the west shoreline of Canada without long haul tide measure records information.
Yutong Zou
Background: Thyroid diseases are highly prevalent worldwide, but their diagnosis remains a challenge. We established reference intervals (RIs) for thyroid-associated hormones and evaluated the prevalence of thyroid diseases in China. Methods: After excluding outliers based on the results of ultrasound screening, thyroid antibody tests, and the Tukey method, the medical records of 20,303 euthyroid adults, who visited the Department of Health Care at Peking Union Medical College Hospital from January 2014 to December 2018, were analyzed. Thyroid-associated hormones were measured by the Siemens Advia Centaur XP analyzer. The RIs for thyroid-associated hormones were calculated according to the CLSI C28-A3 guidelines, and were compared with the RIs provided by Siemens. The prevalence of thyroid diseases over the five years was evaluated and compared using the chi-square test. Results: The RIs for thyroid stimulating hormone (TSH), free thyroxine (FT4), free triiodothyronine (FT3), total thyroxine (TT4), and total triiodothyronine (TT3) were 0.71-4.92 mIU/L, 12.2-20.1 pmol/L, 3.9-6.0 pmol/L, 65.6-135.1 nmol/L, and 1.2-2.2 nmol/L, respectively. The RIs of all hormones except TT4 differed significantly between males and females. The RIs of TSH increased with increasing age. The prevalence of overt hypothyroidism, overt hyperthyroidism, subclinical hypothyroidism, and subclinical hyperthyroidism was 0.5% and 0.8%, 0.2% and 0.6%, 3.8% and 6.1%, and 3.3% and 4.7% in males and females, respectively, which differed from those provided by Siemens. Conclusions: Sex-specific RIs were established for thyroid-associated hormones, and the prevalence of thyroid diseases was determined in the Chinese population.
Method: From January 1, 2014, to December 31, 2018, 280,206 apparently healthy subjects were retrieved from the department of Health Care in Peking Union Medical College Hospital (PUMCH). With ultrasound screening results, thyroid related antibody results and Tukey method being used to exclude outliers, 20,192 apparently euthyroid adults with thorough demographic and thyroid associated results were finally included in this study. Thyroid associated hormones were detected by the Siemens ADVIA Centaur XP automatic chemiluminescence immunoassay analyzer. According to the Clinical Laboratory and standard institution (CLSI) C28-A3, the RIs were calculated as the 2.5th and 97.5th percentiles (P2.5, P97.5) with nonparametric analysis, and compared with the RIs provided by the manufacturer. Additionally, the prevalence of thyroid diseases during whole five consecutive years was evaluated.
Results: The RIs for TSH, FT4, FT3, TT4, and TT3 were 0.71-4.80 mIU/L, 12.2-20.0 pmol/L, 3.9-6.0 pmol/L, 65.6-134.8 nmol/L, and 1.2-2.2 nmol/L, respectively. Expect for TT4, they all showed significant differences between males and females. Respectively, the prevalence of clinical hypothyroidism was 0.5% in males and 0.8% in females, clinical hyperthyroidism was 0.3% in males and 0.6% in females, subclinical hypothyroidism was 3.6% in males and 5.6% in females, and subclinical hyperthyroidism was 2.4% in males and 2.9% in females according to the RIs established in this study, which were different from those reported by the manufacturer. Furthermore, the prevalence of thyroid diseases took on difference for women of childbearing age.
Conclusion: Sex-specific RIs were established for TSH, FT4, FT3, TT4 and TT3 in the Chinese population, and the prevalence of both clinical and subclinical thyroid diseases was evaluated. More attention should be paid to thyroid disorders.
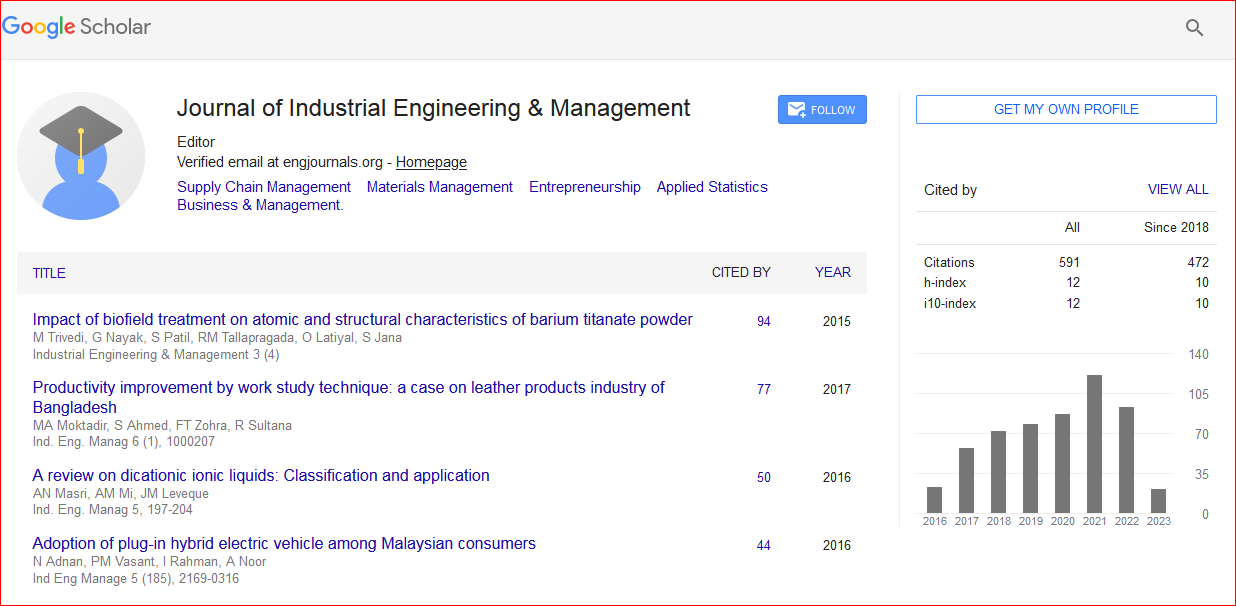
Industrial Engineering & Management received 739 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 