Saudi Arabia
Research Article
Classification of Imbalance Data using Tomek Link (T-Link) Combined with Random Under-sampling (RUS) as a Data Reduction Method
Author(s): Elhassan AT, Aljourf M, Al-Mohanna F and Shoukri MElhassan AT, Aljourf M, Al-Mohanna F and Shoukri M
The problem of classifying subjects into disease categories is of common occurrence in medical research. Machine learning tools such as Artificial Neural Network (ANN), Support Vector Machine (SVM) and Logistic Regression (LR) and Fisher’s Linear Discriminant Analysis (LDA) are widely used in the areas of prediction and classification. The main objective of these competing classification strategies is to predict a dichotomous outcome (e.g. disease/healthy) based on several features. Like any of the well-known statistical inferential models; machine learning tools are faced with a problem known as “class imbalance”. A data set is imbalanced if the classification categories are not approximately equally represented. When learning from highly imbalanced data, most classifiers are affected by the majority class leading to an increase in the false negative rate. Increased.. Read More»
DOI:
10.4172/2229-8711.S1111
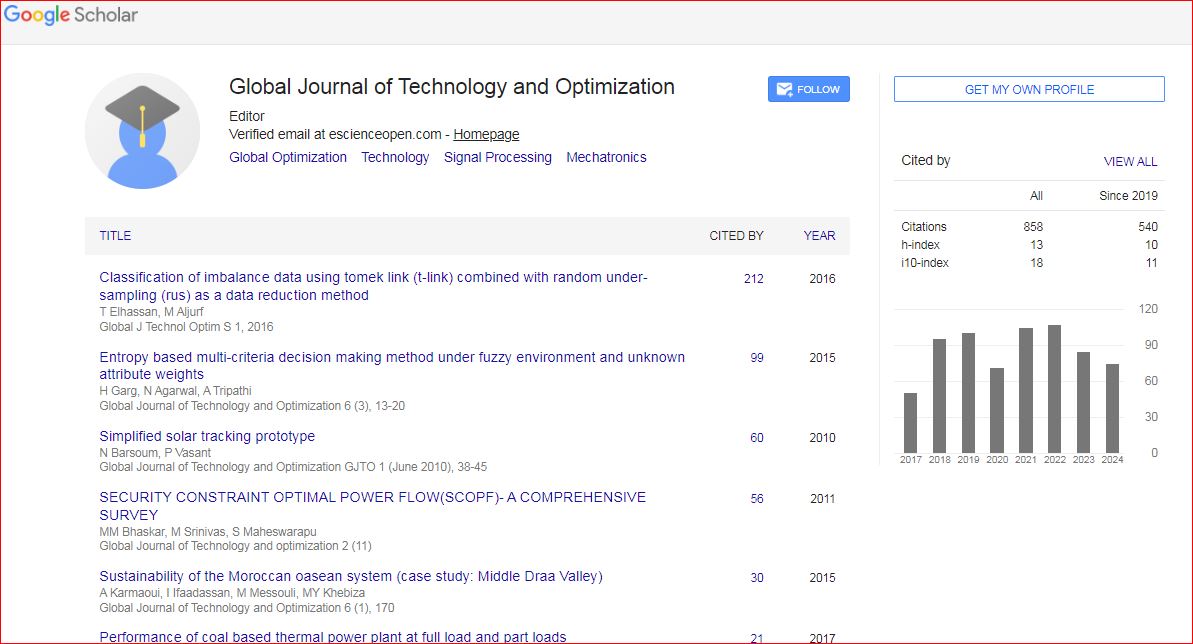
Global Journal of Technology and Optimization received 847 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 