Tanzania
Case Report
Characterizing Clinical Text and Sublanguage: A Case Study of the VA Clinical Notes
Author(s): Qing T. Zeng, Doug Redd, Guy Divita, Samah Jarad, Cynthia Brandt and Jonathan R. NebekerQing T. Zeng, Doug Redd, Guy Divita, Samah Jarad, Cynthia Brandt and Jonathan R. Nebeker
Objective: To characterize text and sublanguage in medical records to better address challenges within Natural Language Processing (NLP) tasks such as information extraction, word sense disambiguation, information retrieval, and text summarization. The text and sublanguage analysis is needed to scale up the NLP development for large and diverse free-text clinical data sets. Design: This is a quantitative descriptive study which analyzes the text and sublanguage characteristics of a very large Veteran Affairs (VA) clinical note corpus (569 million notes) to guide the customization of natural language processing (NLP) of VA notes. Methods: We randomly sampled 100,000 notes from the top 100 most frequently appearing document types. We examined surface features and used those features to identify sublanguage groups using unsupervised clustering. Results: Using the text features we are abl.. Read More»
DOI:
10.4172/2157-7420.S3-001
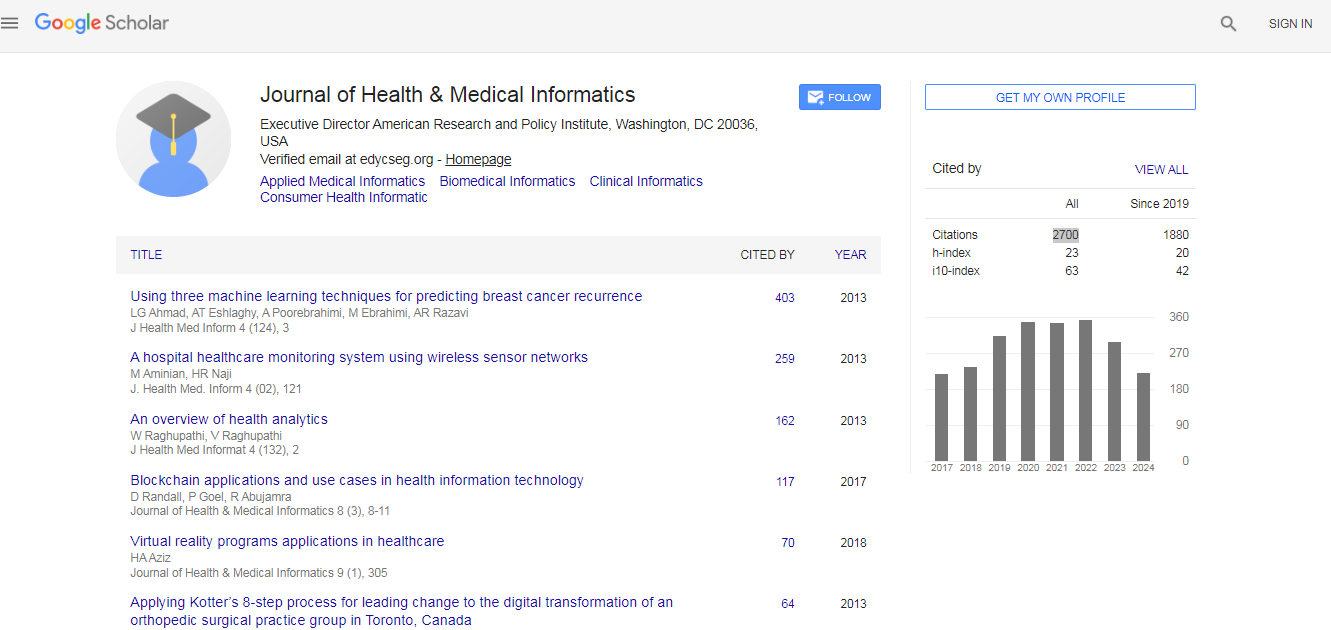
Journal of Health & Medical Informatics received 2700 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 