Mini Review - (2024) Volume 14, Issue 1
Received: 02-Mar-2024, Manuscript No. jpdbd-24-136636;
Editor assigned: 04-Mar-2024, Pre QC No. P-136636;
Reviewed: 15-Mar-2024, QC No. Q-136636;
Revised: 21-Mar-2024, Manuscript No. R-136636;
Published:
30-Mar-2024
, DOI: 10.37421/2153-0769.2024.14.364
Citation: Kairov, Tao. “Building Bridges Navigating the Metabolomic Database Landscape.” Metabolomics 14 (2024): 364.
Copyright: © 2024 Kairov T. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Metabolomics, the study of small molecules or metabolites in biological systems, plays a pivotal role in understanding various physiological processes, disease mechanisms, and environmental interactions. As the field of metabolomics continues to expand, researchers encounter a vast array of metabolomic databases, each offering unique resources and insights. Navigating this diverse landscape of databases can be challenging but is crucial for researchers to effectively leverage available data and advance scientific knowledge. This article serves as a guide to help researchers navigate the metabolomic database landscape, highlighting key databases, their features, and best practices for utilizing them effectively.
Disease • Navigating • Metabolomic
Metabolomic databases serve as repositories for metabolite data generated through various analytical techniques such as mass spectrometry and nuclear magnetic resonance spectroscopy. These databases store information on metabolite identities, concentrations, biological sources, and associated metadata. They play a critical role in metabolomics research by providing access to curated datasets, facilitating data integration, and enabling comparative analyses across different studies and biological systems [1]. Metabolomic databases typically contain extensive libraries of metabolites with annotated chemical structures, molecular formulas, and mass spectra. These libraries enable researchers to identify metabolites detected in their experiments by comparing experimental data with reference standards stored in the database. Metabolomic databases offer user-friendly interfaces for searching and accessing metabolite data. Researchers can query databases using various criteria such as metabolite name, chemical formula, mass-tocharge ratio (m/z), or spectral features. Advanced search functionalities enhance data discovery and retrieval, facilitating efficient data exploration and analysis. Many metabolomic databases support data integration from multiple analytical platforms and experimental techniques.
They provide standardized formats for data deposition and ensure interoperability with other data repositories and analysis tools. This interoperability fosters collaboration and promotes reproducibility across different research studies and laboratories. Metabolomic databases employ rigorous quality control measures to ensure the accuracy and reliability of deposited data. Metadata annotation standards are implemented to capture essential experimental details such as sample preparation protocols, instrument parameters, and experimental conditions. Well-annotated metadata enhance the interpretability and usability of metabolomic datasets, enabling researchers to contextualize their findings effectively [2].
Many metabolomic databases offer built-in analysis tools and resources to facilitate data processing, statistical analysis, and visualization. These tools allow researchers to perform data normalization, feature extraction, multivariate analysis, and pathway enrichment analysis directly within the database environment. Integration of analysis tools streamlines the data analysis workflow and empowers researchers to derive meaningful insights from complex metabolomic datasets. With an increasing number of metabolomic databases available, researchers must navigate the landscape strategically to identify databases that best suit their research needs. Define your research objectives and determine the type of metabolomic data required to address your scientific questions. Some databases specialize in specific biological domains or analytical platforms, while others offer broad coverage across multiple research areas. Assess the scope and coverage of metabolomic databases in terms of metabolite diversity, sample types, and species coverage. Choose databases that align with your research interests and provide comprehensive data relevant to your study system [3].
Evaluate the quality of metabolomic data deposited in databases, including metadata completeness, data integrity, and consistency. Prioritize databases with robust quality control procedures and comprehensive metadata annotation standards to ensure the reliability of the data retrieved for analysis. Consider the user interface design, accessibility features, and ease of navigation when selecting metabolomic databases. Opt for databases with intuitive interfaces, advanced search capabilities, and user-friendly documentation to streamline data exploration and retrieval processes. Explore the level of community support, user engagement, and available resources associated with metabolomic databases. Engage with online forums, user groups, and support channels to seek assistance, share knowledge, and collaborate with other researchers using the same database platform. Several metabolomic databases are widely used by the research community due to their comprehensive datasets, advanced features, and user-friendly interfaces.
HMDB is a comprehensive resource containing detailed information on human metabolites, including chemical structures, pathways, biofluid concentrations, and disease associations. It offers advanced search functionalities, spectral databases, and pathway analysis tools for exploring metabolomic data in the context of human physiology and pathology. MetaboLights is a public repository for metabolomics data generated from a wide range of species and experimental platforms. It supports data submission, storage, and sharing, with emphasis on standardized metadata annotation and data integration. MetaboLights provides access to curated metabolite libraries, experimental protocols, and analysis tools for facilitating open science and data-driven discovery [4].
Mass Bank is a mass spectral database that archives high-resolution mass spectra of metabolites obtained from mass spectrometry experiments. It offers spectral search capabilities, spectral libraries, and structure elucidation tools for identifying unknown compounds based on spectral matching. Mass Bank serves as a valuable resource for metabolite identification and structural characterization in metabolomics research. The Metabolomics Workbench is a comprehensive data repository and analysis platform for metabolomics research. It hosts metabolomic datasets from diverse species, experimental designs, and analytical platforms, with emphasis on data standardization and integration. The Metabolomics Workbench provides analysis tools, statistical workflows, and data visualization options to support hypothesis-driven research and exploratory data analysis [5].
Adhere to established data standards and metadata annotation guidelines when depositing or accessing metabolomic data in databases. Standardized data formats and metadata facilitate data integration, interoperability, and reproducibility across different studies and platforms. Integrate data from multiple metabolomic databases to leverage complementary datasets and analytical resources. Cross-database integration enhances data coverage, facilitates comparative analyses, and expands the scope of research inquiries across different biological systems and experimental contexts. Foster a culture of collaborative data sharing and open science by depositing metabolomic data in public repositories and sharing data with the research community. Collaborative data sharing accelerates scientific discovery, promotes transparency, and enhances the impact of metabolomics research on global health and environmental challenges. Stay updated on emerging trends, technologies, and best practices in metabolomics by participating in training programs, workshops, and online courses. Continuously expand your knowledge and skillset in metabolomic data analysis, interpretation, and database utilization to enhance the effectiveness of your research endeavors [6].
Metabolomic databases play a vital role in advancing our understanding of biological systems, disease mechanisms, and environmental interactions through the integration and analysis of metabolite data. Navigating the metabolomic database landscape requires careful consideration of database features, data quality, and research objectives. By selecting appropriate databases, adhering to best practices, and fostering collaborative data sharing, researchers can harness the power of metabolomic databases to accelerate scientific discovery and address complex biological questions with confidence. Building bridges across the metabolomic database landscape facilitates interdisciplinary research collaborations, promotes data-driven innovation, and enhances the impact of metabolomics on human health and environmental sustainability.
None.
None.
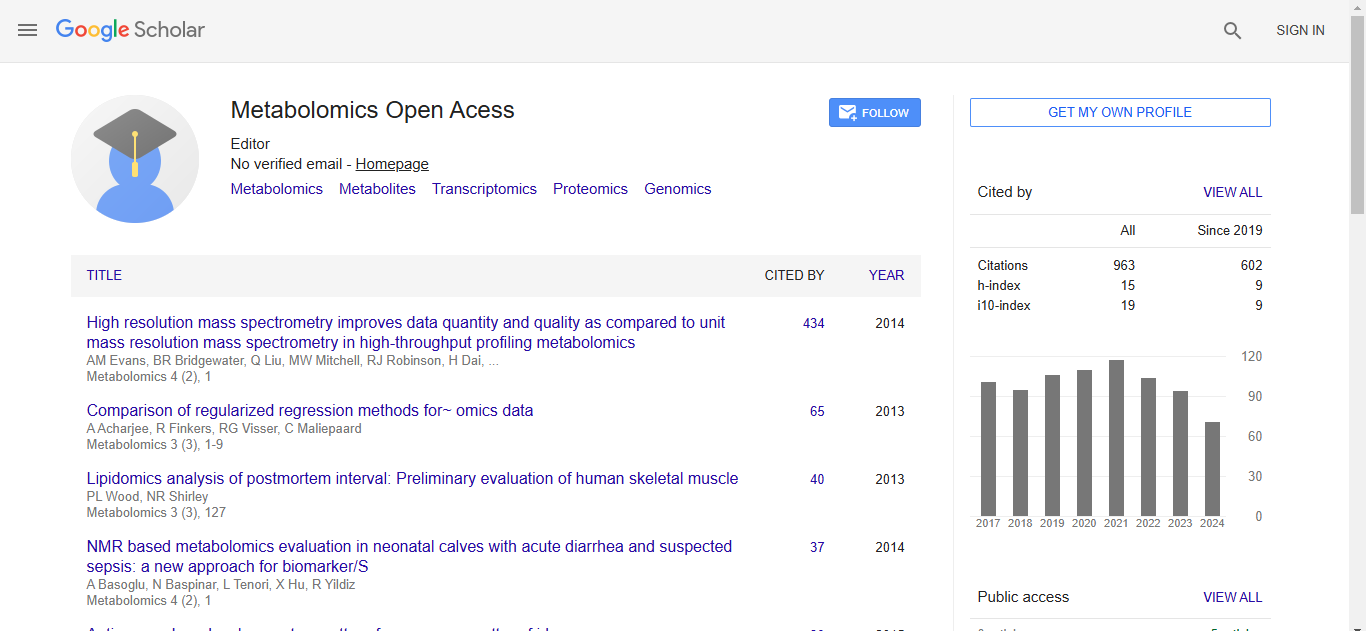
Metabolomics:Open Access received 895 citations as per Google Scholar report