Brief Report - (2022) Volume 11, Issue 10
Received: 22-Sep-2022, Manuscript No. pbt-23-86240;
Editor assigned: 28-Sep-2022, Pre QC No. P-86240;
Reviewed: 17-Oct-2022, QC No. Q-86240;
Revised: 23-Oct-2022, Manuscript No. R-86240;
Published:
30-Oct-2022
, DOI: 10.37421/2167-7689.2022.11.333
Citation: Leo, Nicky. “Drug Detrimental Reactions Mechanically Extracted from Product Characteristics” Pharmaceut Reg Affairs 11 (2022): 333.
Copyright: © 2022 Leo N. This is an open-access article distributed under the terms of the Creative Commons Attribution License, which permits unrestricted use, distribution, and reproduction in any medium, provided the original author and source are credited.
Drug item names are required administrative records as part of each medication's marketing approval. They provide up-to-date and comprehensive information regarding the risks, benefits, and pharmacological properties of promoted prescriptions. As a result, a few applications in the field of medication wellbeing reconnaissance and evaluation would benefit from separating the clinical information stored in item names and making it accessible as computationally open information bases. For instance, it is crucial to determine whether an examined adverse drug reaction (ADR) is currently referred to as [1] during post-advertising health assessments. ADRs that are organized and machine-readable do not yet exist. As a result, separating ADRs from unstructured item marks becomes an intriguing research topic. Numerous studies concentrate on transforming unorganized ADRs information into machine-coherent information. However, the majority of current studies focus on the US version of product names. Using a variety of regular language handling (NLP) techniques, such as named substance acknowledgment, rule-based parsing, and NegEx, frameworks like SPLICER and SPL-X were created to separate ADR terms from particular segments. The primary research question in this review is how to use natural language processing (NLP) techniques to naturally distinguish ADRs from normalized European item marks, specifically SmPC [2]. We first develop a NLP pipeline to remove unfavorable medication responses from SmPC in order to address the question. The terms that were removed are used to create a database. The following summarizes the fundamental characteristics of the information base and the NLP pipeline: a) reproducible and open-source; b) adaptable to related last-minute projects; c) a database of information that is useful for medical examinations.
The researchers show the SmPC information source, discuss the various NLP techniques used to remove ADRs from SmPC, and briefly explain the evaluation system used to approve our programmed ADR extraction method. The first step is to delete the information about incidental effects from the Electronic Medications Abstract (EMC). The ADRs are then appropriately extracted at that point. Finally, both NLP and clinical specialists evaluate our NLP strategy's presentation [3,4]. First, we distinguish a rundown of primary elements in the HTML selections, such as the counts and locations of some MedDRA expressions, such as SOC (Framework Organ Classes) and recurrence [5]. Second, the highlights are designed from scratch in the HTML records. We establish three fundamental primary classes based on the elements: free text, organized text, and even.
The results of the survey for manual specialists show that the method we proposed is effective and can be used to address clinical issues related to ADR. In particular, our method achieves an accuracy of 0.932 and a general review of 0.990. In previous investigations that concentrated on distinguishing ADRs from SPLs, this superior execution has never been explained. First and foremost, there are no normalized ADR comments available for benchmarking ADR extraction strategies in light of the SmPC. It is difficult to recreate this study's presentation. Different execution scores could be uncovered by conducting manual surveys with a variety of experts. This review's manual audit cycle imposes one more restriction. Given their busy schedules, including clinical specialists in the manual survey process is always challenging. The Covid has made things worse. As a result, there was only one clinical master in this concentrate's manual cycle. We added a clinical NLP master as a second commentator to make up for this. The clinical master prepared the NLP master for the assignment and knows everything there is to know about it. In a post-Coronavirus world, we intend to expand the manual survey to a larger number of tests and clinical specialists to address this issue.
Using standard articulations, commotion in the removed terms can be cleaned up. Regarding the unsplit ADRs, we can add more options to the split capability to allow strings to be separated by a semicolon, "and," or "or." Additionally, if separate ADR terms are encoded into MedDRA Favored Terms, non-ADR errors may be reduced, allowing for further work on the presentation. Based on data from the UK's EMC, the proposed ADR extraction method was developed. Despite this, item marks in the UK might change as a result of Brexit. The method won't then work as well as shown in this review at that point. The use of the EMA's SmPCs ought to be the primary focus of any further development of this strategy.
This investigation has two-fold commitments. To begin, it contributes to the field of clinical NLP by demonstrating a reproducible, open-source method for separating ADR terms from the SmPC. We believe that our approach could be useful in the SmPC's handling and coding of ADRs because the superior exhibition scores show that it is extremely successful. The following commitment is made in the medical field. Our method of extraction resulted in organized data depicting showcased prescriptions as well as their recorded ADRs and frequency. From aiding in the identification of ADRs in patients to ADR evaluation in clinical preliminary studies, such an information base could be utilized to address practical clinical issues.
None.
The authors declared no conflict of interest.
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
Google Scholar, Crossref, Indexed at
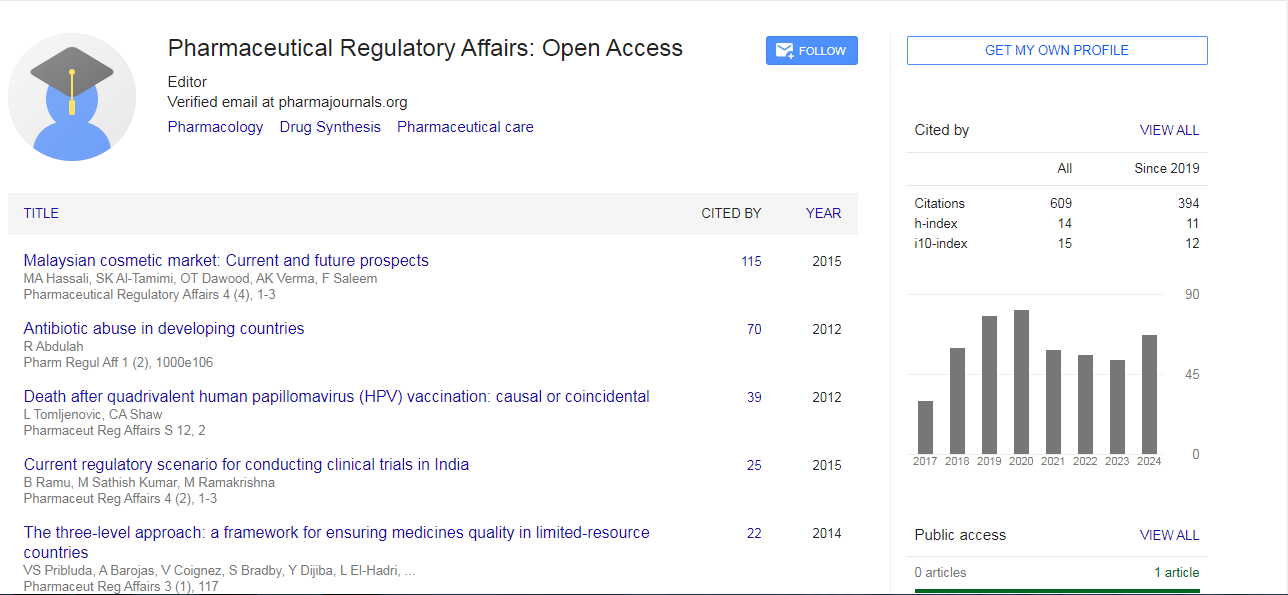
Pharmaceutical Regulatory Affairs: Open Access received 533 citations as per Google Scholar report