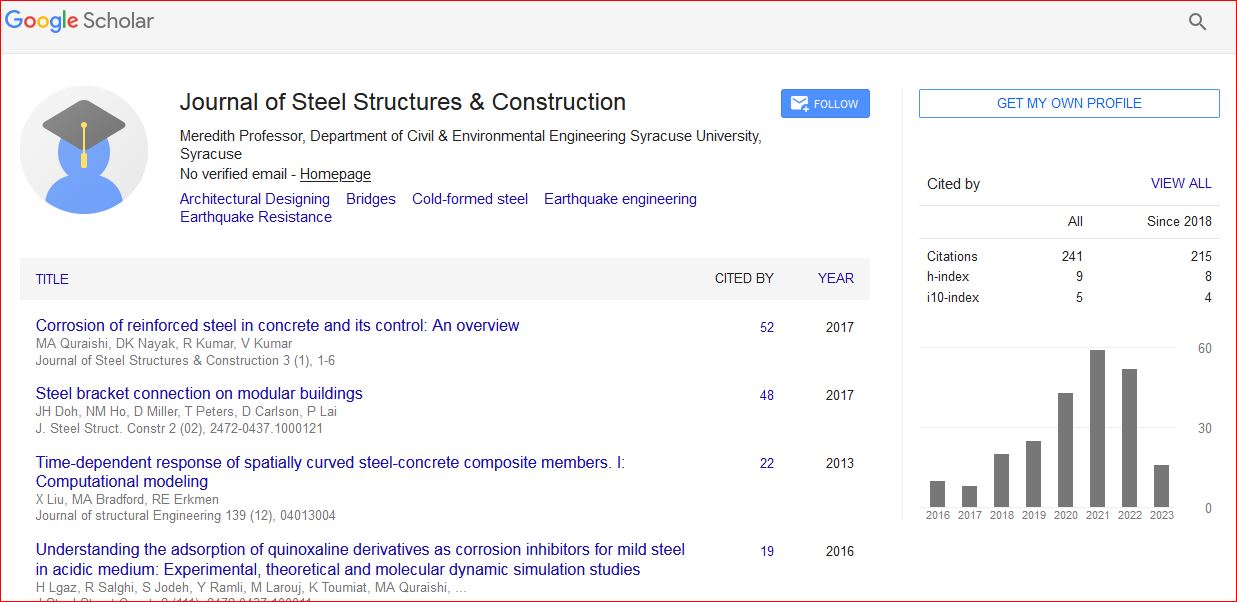
Review Article - (2024) Volume 10, Issue 3
Received: 01-Jun-2024, Manuscript No. JSSC-23-88730;
Editor assigned: 02-Jun-2024, Pre QC No. P-88730;
Reviewed: 16-Jun-2024, QC No. Q-88730;
Revised: 23-Jun-2024, Manuscript No. R-88730;
Published:
30-Jun-2024
, DOI: 10.37421/2472-0437.2024.10.187
Citation: Golmah, Vahid, Shahram Bpzorgnia and Mina Tashakori. "Proposing a New Model Based On Bayesian Network as Automated Planner of Pickup and Delivery in Inventory for Steel Industry." J Steel Struct Const 10 (2024): 187.
Copyright: © 2024 Golmah V, et al. This is an open-access article distributed under the terms of the creative commons attribution license which permits unrestricted use, distribution and reproduction in any medium, provided the original author and source are credited.
Today, material pickup and delivery is the most important process for inventory planning of manufactures. Human operators usually schedule resources for pickup and delivery that it needs high cost and time and mistake decision cause to tiredness and pressure work. This problem is more acute for the steel industry. Therefore, using of an efficient expert system based on Artificial Intelligence (AI) could eliminate limitations of human planner that it has not applied for inventory planning in steel industry yet. In order to imbed a learnable model from decision patterns of human planners in steel industry, we propose an automated planner for pickup and delivery in raw/semi products of steelmaking based on Relief Bayesian Network (RBN). The proposed approach is applied for Mobarakeh steel company that results show the proposed approach decides as same as human planner for inventory.
Vehicle Route Problem (VRP) • Pickup/delivery decision • Machine Learning • Bayesian Network (BN) • VRP with Time Windows (VRPTW)
Vehicle Routing Problem (VRP) is family of combinatorial optimization problems that it includes whole class of problems involving the design of optimal routes for a fleet of vehicles to service a set of customers subject to side constraints [1]. The VRPs are much-studied problems due to their many important practical applications. There are multiple variations on VRP, with a few of them being [2]:
• VRP with Pickup and Delivery (VRPPD) have packages are
picked up and delivered between certain locations.
• VRP with Time Windows (VRPTW) have time constraints
for each customer.
• Capacitated VRP (CVRP) have constraints on the vehicles load
capacity.
• Open VRP (OVRP) where there is no depot data through
telematics.
In the last decade, the integrating of VRP with other related decision problems has been constantly growing (Figure 1 shows a sample problem for it). Despite the complexity of these problems, advances in optimization techniques and technological advances have made it possible to study them due to the benefits derived from simultaneous optimization of interrelated problems. One of the most studied classes of integrated VRPs is the class of problems that integrate vehicle routing and inventory management decisions for planning of pickup and delivery raw/semi-product/finished products for transport material to equipment for increasing efficiency of production. Manufacturing companies are continuously seeking efficiency to overcome the difficulties related to the raw/semi-products dynamics and the changing inventory environment [3].

Figure 1. Exhibitation of an integrated VRP and pickup and delivery for a sample problem.
Concentration of iron ore, lime and sludge as raw material and pellet as semi-products are the part of the steel supply chain that deals with the transportation related to direct reduced iron (sponge iron) production at direct deduction platforms and pellet at pelletizing. Materials must be transported to direct deduction and pelletizing plants in order to prevent the production of sponge iron and pellets from being halted due to the lack of supplies and empty modules. Transportation task is the delivery of materials from a land base to the pelletizing and direct reduction platforms. Any disruption in supplying of material to pelletizing and directed reduction platform could decrease production of pellets as arrival material to direct reduced and production of sponge iron as arrival material to steelmaking process, respectively and decrease efficiency of iron manufactory as well as increasing of constant costs. The proper scheduling of material transportation at pelletizing and direct reduction platforms is therefore essential for reducing costs and improving production efficiency. Although, technology progresses in many fields at recent decades but many companies still relying on human operators for dispatching incoming deliveries to vehicles. Based on vehicle location, current load, package type, and fleet dispatcher's experience, fleet dispatchers determine which vehicle is most suitable to make a new delivery. Acquiring experience takes a long time and due to stress; their careers are often short, which leads to low supply of good dispatchers. Automated decision making could provide dispatchers with vehicle suggestions to ease their workload, and in the future potentially replace human dispatchers altogether [4]. We will focus on learning of human dispatchers’ decisions. Some advantages of this approach are that the model can learn complex latent variables, e.g. certain drivers are more suitable for carrying heavy packages, and it has less computationally demanding during inference since no route optimization is performed.
In other word, studying problem is responding to question: “Which equipment from which pile in inventory pick up special material for supply needs of modules in direct reduction platform as extracted decisions be as same as human decision making?”
Today, Bayesian Belief Networks (BBN) or Bayesian Network (BN) has become a popular and dominant representation for encoding uncertain expert knowledge in expert systems in areas such as quality evaluation, medicine, financial analysis, risk management, project management etc. It is a probabilistic model as a systematic formalism based on artificial intelligence for data representation and reasoning under conditions of uncertainty. The bayesian network encodes probabilistic relationships among variables of interest in an uncertain reasoning problem and show them as graphical model [5]. The BBN has four basic features which are useful in graphical probabilistic modeling and best met our modeling need [6]:
• Bayesian networks can handle incomplete datasets by encoding
dependencies among all domain variables.
• A bayesian network makes it possible to learn causal
relationships, and it use to understand domain of problem and to
predict the consequences of intervention.
• Bayesian network is an ideal representation for combining
prior knowledge and data because it has both a causal
and probabilistic semantics.
• Bayesian methods in conjunction with bayesian networks
and other kinds of models offers an efficient approach for avoiding
the over fitting of data.
On the basis of these factors, and also the awareness of the inventory environment, pickup/delivery planning of raw material and semi-products with constraints related to environment in logistics based on bayesian network has been the subject of contribution in this article.
This paper is organized as follows: Section 2 provides a systematic literature review of the automated dispatching problem. In section 3, we present a new integrated inventory planning and bayesian network model for automated dispatching problem with considering the limitation of raw material and equipment. In section 4, the applications of proposed approach on real problem describe to solve the proposed model. The computational analysis proposes in section 5. Finally, the conclusions and future suggestions provide in section 6.
For automated dispatching, the integration of routing and location problems had not been considered till 1970 [7]. Potvin, Shen, and Rousseau proposed an automated dispatching based on neural network to estimate a vehicles quality for a specific delivery and then pick the vehicle with the highest quality score. To incorporate the information about the other vehicles, they translated the inputs based on the best attribute value across all vehicles. The used routing expert to create the data set was not a professional dispatcher and the deliveries simulated. The results were however promising with the model selecting the same vehicle as the human dispatcher in 89% of the test samples.
Shen, et al. develop a program to assist dispatchers in an express mail company without capacity constraints by concentrating to automated dispatching for delivery commodities by each delivery they estimated the travel time by minimizing the cost of inserting the pickup and delivery location in the existing routes and the additional lateness introduced from inserting the pickup and delivery location. A dispatcher is assumed to have 90 deliveries and corresponding decisions as training data and 50 deliveries as testing data. The used approach for automated dispatcher was a 3-layer backpropagation neural network. Features extracted from a single driver, and they were used as input and the output was a single quality score (1 for select driver, and 0 otherwise). The model output for each driver ranked and compared to the dispatcher’s decision. Experiments showed the network perform close to the human dispatcher in empty travel time, lateness at pickup, and lateness at delivery.
Chen, et al. introduced a Data Mining based Dispatching System (DMDS) to learn dispatching rules in intermodal freight industry. They used decision trees to learn the rules and the learned rules used as input to an optimization algorithm to improve on the dispatcher’s results. They used complemented load attributes such, e.g., pickup and delivery location, start and end time of a load, required trailer type, with driver attributes like the drivers start and end time, home location, and remaining work hours. The most important attributes were distance between load and driver, difference between a driver remaining work hours and a load’s service duration, estimated remaining time for a driver to finish current task, and the drivers remaining work hours based on the trained decision trees. They showed that their hybrid proposed approach based on optimization algorithm and DMDS give a small performance improvement compared to an optimization only approach. They also showed that training the DMDS with the optimized solutions give slightly better results, 5.6% lower empty travel mileage and 1.5% reduction in empty ratio [8].
Vukadinovic, Teodorovic, and Pavkovic developed an approach based on neural network to learn decisions about loading, transport and unloading of gravel by inland water transportation. Their goal was predicting the number of barges assigned to each tug. The input was the suitability for barge i to be assigned to tug j, where suitability was a function of tug’s j barge capacity and the difference in release time for the barge and tug. They use a heuristic simulated annealing to train network. Their designed network trained on 56 samples and tested on 16 test samples. The network performed slightly worse than the dispatcher but was promising.
Riessen, Negenborn, and Dekker developed a system for real time container transport planning to provide instant decisions for incoming orders. They concentrated decision trees to determine which service (train, barge and truck) is better to use for a single container. They used historical data to train the decision tree and then learned rules used to train the model. Their experiments showed that proposed model could reduce transportation costs by 3% over a greedy approach.
Mojtaba Maghrebi, Claude Sammut, and Travis Waller developed a model for dispatching Ready Mixed Concrete (RMC) problem. The customer priorities for dispatching ready mixed concrete done by decision trees. Their used features included distance to depot, unloading time, travel time, required amount etc. The proposed model tested by simulating a plant with three customers for 200 days then data sent to a human dispatcher to prioritize. The data separated to training and testing (90-10 split) data set and the model reached an 80% accuracy.
Adane and Ramesh consider the safety features of Bishoftu Pickup Vehicles (BPV) to improve crashworthiness of the existing Bishoftu pickup vehicle through remodeling. The obtained results of used model modify energy absorbing components and give better crash performance [9].
Bing, et al. concentrated to local freight train transit system in railway terminal and formulate it as a mathematical programming model. Their objective functions was engines’ operating cost, wagons’ travelling cost, and penalty cost for exceeding the retrieval time window. They propose a novel two-stage hybrid optimization procedure based on coding task sequence, dividing task batch, and generating access to order sequence population.
Shouqiang, et al. propose a new form of customized bus service with heterogeneous fleets and multiple candidate locations for customized bus services with homogeneous fleet and single location selection to passengers. Moreover, the propose two inserting operators to deal with the problem with multiple candidate locations and analyse its influence on the results. They verify the effectiveness of their proposed approach based on its implication on a small scale case on a simplified Sioux waterfall network and a large scale problem in Beijing, China. The result shows that outperform other algorithms in searching for more satisfying solutions with higher efficiency.
Problem description
Today, steel industries face rapid global economic integration and market competition growth. Therefore, steel plants need to provide on time delivery, accurate delivery, and improved utilization of equipment to meet high efficiency. Due to the bulky machines and high operating costs, inventory planning of raw material and logistic them as major part of production planning plays an important role in steel factories. The inventory planning is to schedule machines and processes in the transportation to production lines across manufactory according to due dates, product types, quality requirements, and machine capacity. The quality of inventory planning can directly affect the performance of a steel factory.
The pelletizing and directed reduced platform are the most important units in process of steelmaking that any interrupt in transportation planning to them can fail performance of all plants in factory and in result reduce total efficiency. Therefore, one of major challenges in many steel making manufactories is pickup and delivery planning of raw material and semi production on inventory as plants does not stop due to lack of needed material. In other hand, some of pickup and delivery equipment have constraints that could not work in some situation. Another problem in pickup and delivery planning is finding location to stack raw material and produced sponge iron from directed reduced platform. Assigning location to any arrival raw material should do with manner that their pickup will fulfill easily at future. Therefore, pickup and delivery are mixed and dependent together that it results pickup and delivery planning be a complex problem to solve for steel industry. Pellets have two types include purchased pellet and produced pellet that they have semi-products nature. The raw materials are included fine-grained iron ore, coarse-grained iron ore and lime [10].
All of materials transport by conveyor belts and pickup by reclaimers and deliver by stackers. The conveyor belts do not have any constraint and locate through inventory. As it is shown in Figure 2, the inventory of raw/semi-produce includes six parks (five main parks and one emergency park). Parks 1-5 are main parks, which have equipment to stack and reclaim. Park 0 is an emergency park which any stacking or reclaiming on it is done manually and it is used for only emergency situation that it is impossible to stack or reclaim on parks 1-5. The park 1 often uses for pellet and park 2-5 are used for all of material types. Any park can divide to one or several pile and materials stack on piles. Size of pile are dynamic and could change based on environment situation, but the used for special type of material could not change.

Figure 2. Exhibition of parks and pile on inventory of raw material and semi products.
Any pickup and delivery equipment has special properties. Three reclaimers named to bridge reclaimer 1, bridge reclaimer 2 and boom reclaimer do the pickup tasks. Two bridge reclaimers reclaim materials downward and could have uniform pickup. Therefore, they usually used for iron ores. The bridge reclaimer 2 only reclaims one side and could not pickup materials that are located on its rear. Inventory planning should consider assumption of one sided constraint in bridge reclaimer 2 as avoid facing situations that it locates back of piles. The bridge reclaimer 1 could reclaim on both sides and has less constraint for pickup. The boom reclaimer reclaims material upward and it usually used for iron ore and pellet. Boom reclaim has not any constraint for pickup materials and could transfer across parks and piles.
The inventory is equipped with three stackers for deliver materials. The stackers locate between parks as stacker 1 is between park 0 and park 1, stacker 2 is between park 2 and 3 and stacker 3 between park 4 and 5 and could move among piles freely [11].
It is popular that inventory planning is done by human inventory planners in many steel manufactories. Inventory planners’ analysis demand of other units and decide what material on which pile by which equipment whether deliver or pickup based on their experience. Acquiring experience takes a long time and due to stress, their careers are often short, which leads to low supply of good dispatchers and replacement of planners results to increase costs of mistake decisions. Therefore, it is vital to develop an expert system based on artificial intelligence to learn from decision patterns of human planners. Therefore, studying problem in our article is developing of automated planner to produce reliable, repeatable decisions similar to decisions by human inventory planner [12-16].
Solution approach
We use a new approach based on Bayesian Belief Networks (BBN) or Bayesian Network (BN) to develop an expert system that enable to make pickup/delivery decisions of inventory similar to human planner in steel industry. In this section, BNIP, our proposed bayesian network based inventory planning model is introduced. Figure 2 shows the architecture of BNIP. The main architecture of BNIP contains the following modules:
• Discretizing the continuous pickup/delivery of inventory planning
values in dataset.
• Creating the structure or topology of the bayesian network by
means of the structure learning algorithms.
• Calculating the conditional probability distributions for each node
in the network using the parameter learning algorithm.
• Validation of learned model based on bayesian Network by
execute in on testing data and to compare predicted decisions by
model and actual decisions by human inventory planner. The rest
of this section describes the aforementioned modules in detail.
The pickup/delivery plan of inventory gather on a data set based on environment situation and human decisions. The used feature in our model has extracted from Fagerlund’ features due to they show their used features outperform model and result to behavior same as human planner. The features are shown in Table 1.
| Name | Description |
|---|---|
| L type | Task type (1: Stack, 2: Delivery) |
| LN load | Material (1: Fine grained iron ore, 2: Coarse grained iron ore, 3: Produced pellet, 4: Purchased pellet and 5: Lime) |
| LS time | Start day |
| LE time | Finish day |
| L curloc bridge 1 | Bridge reclaimer 1 location |
| L curloc bridge 2 | Bridge reclaimer 2 location |
| L cur boom | Boom reclaimer location |
| SLd stacker | Current using stacker (-1: all of stackers are idle, park no otherwise) |
| SDL reclaimer | Current using reclaimer (-1: all of stackers are idle, park no otherwise) |
| LDLOC | Park no of pickup/delivery |
| D driver | Used equipment (1: Bridge reclaimer 1, 2: Bridge reclaimer 2, 3: Boom reclaimer, 4: Stacker 1, 5: Stacker 2 and 6: Stacker 3) |
Table 1. Used features based on the features from Fagerlund, et al.
This data includes pickups, deliveries, and their associated equipment that have been assigned to any record. The selection of a park and pickup/delivery equipment made by human planner. The data also contains the other equipment, which was active at decision time (Figure 3).

Figure 3. The framework of our proposed approach as schematically.
The target is therefore the park and pickup/delivery equipment selected by the human planner and the goal is for the algorithm to select the same park and pickup/delivery equipment as the human planner did from a set of parks and pickup/delivery equipment [17].
As it said before, the assumption of dependency among decision parameters of pickup and delivery in inventory planning is more realistic. Therefore, probability models based on BN can regard this assumption. There are two main approaches to build a BN structure include created network structure by a specialist who manually determines the location and the direction of the edges among the edges an learned network structure by some learning algorithms applied on a data set. The first approach requires a great deal of skill as well as communication with domain experts that is a labor intensive, expensive, and time-consuming task. Therefore, we use second approach to create structure of BN.
Many approaches have proposed in the literature for learning the structure and parameters of a BN from data. These approaches work under the assumption that all the variables in the domain are discrete tests, or continuous with gaussian (normal) distribution, whereas some of our used features have continues values that we must use a normality test to check it. Several test such as goodness of fit graphical assessment of normality, Shapiiro-wilk’s test and D’agotino is developed and deployed in many research. Among all of developed normality tests, chi-square goodness of fit test is more efficient and popular to test normality of the dataset variables for its ability to use for any univariate distribution. The chi-square test regards two hypotheses as H0 (the values follow gaussian distribution) and H1 (the values follow gaussian distribution) and then calculates the chi-square statistics for the Gaussian distribution. If the calculated chi-square statistic is greater than the critical value at significance level α, then the null hypothesis rejects, otherwise the null hypothesis accepts [18]. If satisfy the discrete or continuous with gaussian distribution assumption, the initial step in modeling a problem with bayesian network is structuring of a bayesian network to capture qualitative dependencies among variables of the network. As two nodes is connected with a directed edge if one affects or causes the other that we use K2 algorithm to do it because of its efficiency and popularity for structure learning in bayesian networks. The K2 algorithm is a score based structure learning algorithm that uses a greedy approach to learn about the network structure from data. It aims to find the network structure with maximization the networks’ posterior probability. Given the experimental data, the K2 algorithm uses a prior ordering of nodes so that if node xi precedes node xi in the ordering, then, the node xi cannot be a parent of node xi in the structure. Thus, this ordering could reduce the computational complexity. One of the most important challenges in using the K2 algorithm for structure learning of a bayesian network is determining of the initial order of nodes [19].
The used approach to Identifying the initial order of nodes is using of Maximum Weight Spanning Tree algorithm (MWST) that it is a popular to extract subset of the edges that connects all the vertices together, without any cycles and with the maximum possible total edge weight. First, the MWST approach assigns prior probability as initial weight to each edge and then finds the optimum set of n-1 first order dependency relation among n variables. The topological order with the maximum possible total edge weight resulted by the MWST algorithm can be used to initialize the K2 algorithm.
Once the structure of the bayesian network is constructed, it is necessary to learn the bayesian network parameters by specification of conditional probability distribution for each node. Maximum Likelihood Estimation (MLE) algorithm is an efficient and popular method to learn the bayesian network parameters. The MLE algorithm first estimates the joint distribution and then calculates the conditional probability distributions for each node of the constructed discrete bayesian network. The learned bayesian network can be used to show decisions of pickup/delivery in inventory planning which doesn’t see simply.
Experiments conducted to show how the pointed problems on pickup and delivery planning of inventory solved. We suggest a planner system based on Bayesian Belief Networks (BBN) or Bayesian Network (BN) combined to decide as same as human planner of inventory to evaluate effectiveness of the proposed approach, it is executed on real dataset that gathered from Mobarakeh steel company as the biggest steel producer in Iran since January to March 2019. The used data set include 160 records (120 records as training set and 40 records as testing data set). The supporting machine was a Lenovo computer with a core i 5 2.0 GHz CPU and 6 GB RAM [20].
As is described in the previous section, some of planning parameters in our dataset have continuous values. With regard to the aforementioned aspects of the bayesian network learning, our dataset can use for learning under the assumption that all 11 planning parameter values have gaussian (normal) distribution. To identify that our dataset variables have gaussian distribution or not, we use chi-square goodness as normality test. The most frequently used significance level in chi-square test is 0.05.
We use easy fit to perform the chi-square goodness of fit test on our dataset. The easy fit is a type of data analysis and simulation software integrated with microsoft excel to automatically or manually fit many distributions to a dataset and selects the best distribution. The chi-square goodness resulted from executing of easy fit on our dataset is shown in Table 2.
| Parameter | Chi-square statistic | Critical value | Alpha | Reject H0 |
|---|---|---|---|---|
| L type | 71.44 | 12.59 | 0.05 | Yes |
| LN load | 92.55 | 5.99 | 0.05 | Yes |
| LS time | 4.12 | 11.07 | 0.05 | Yes |
| LE time | 17.77 | 3.84 | 0.05 | Yes |
| L Curloc bridge 1 | 120.54 | 5.99 | 0.05 | Yes |
| L Curloc bridge 2 | 136.52 | 3.84 | 0.05 | Yes |
| L Cur boom | 98.25 | 13.59 | 0.05 | Yes |
| SLd stacker | 26.39 | 10.87 | 0.05 | Yes |
| SDL reclaimer | 86.65 | 19.27 | 0.05 | Yes |
| LD LOC | 93.25 | 25.39 | 0.05 | Yes |
| D driver | 19.56 | 11.45 | 0.05 | Yes |
Table 2. Resulted chi-square statistic to test normality of any parameter.
As it is shown in Table 1, the resulted chi-square goodness statistics is greater than determined significance level (Alpha=0.5) for any planning parameter that it means of rejecting H0 hypothesis (The planning parameter values in our dataset follow the gaussian/normal distribution). Therefore, none of planning parameter values in our dataset does not have gaussian/normal distribution and it is necessary to discretize planning parameter values. We use hard discretization to split parameters value to numerical domain of a continuous attribute. The motivation of using of hard discretization is that the samples near to disjunction points will end up in different intervals despite the fact that they were neighbors in the original continuous form. However, the number of bins in hard discretization effects on accuracy of pickup and delivery planning in inventory environment. Thus, we use different values (5, 10 and 15) as number of bins for discretization of planning parameter values by using of hard discretization and analysis resulted evaluated performance.
In order to proper decision based on planning parameters to help user for planning of pickup and delivery, we use learned bayesian network. We use Matlab 2015 software to execute Maximum Weight Spanning Tree algorithm (MWST) for identifying the initial order of nodes to extract subset of the edges that connects all the vertices together, without any cycles and with the maximum possible total edge weight. The implementation of bayesian network done by using of Netica and resulted learned bayesian network from our dataset shown in Figure 4.

Figure 4. The resulted learned Bayesian network for pickup and delivery planning of inventory.
In parameter learning phase of BNs, conditional probabilities for the levels of any node can obtain after propagating the evidences through the network. For example, a decision of human inventory planner, which occurred in any day, let the following evidences be observed at decision time. The bridge reclaimer 1, bridge reclaimer 2 and boom reclaimer are located on park 5, 3 and 1 respectively, task is stacking of fine-grained iron ore, and the used reclaimer is 3 and all of stackers are idle. Given these evidences, the BN estimated indicates that the most likely decision for this delivery task seems to stack on park 1 with a probability 35.3% and by Stacker 1 with a probability 25.9%.
The following measurements, which often used to evaluate the efficiency of the expert systems, used in this research:
• True Positive (TPi): The number of sample that is correctly
classified into the ith class.
• False Positive (FPi): The number of samples being wrongly
classified into the ith class.
• True Negative (TNi): The number of outer samples that is
correctly classified.
• False Negative (FNi): The number of ith class samples which is
wrongly classified into the other classes.
• Precision=ΣTPi/ΣTPi+FPi
However, automated planners were evaluated using 4-fold cross validation, which is a technique for estimating the performance of a classifier. First, the original samples are randomly partitioned into 4 subsets. Secondly, one subset is singled out to be the testing data and the remaining 3 subsets are treated as training data. Afterwards, the cross validation process repeat 4 times and the estimation accuracy of the classifier can be evaluated by the average accuracy of the four estimations.
To illustrate the effectiveness of the proposed algorithm, the experiment results shown Figure 5. As shown in Table 2, the precise of prediction of decision for the proposed algorithm is 95% and 92.5% for used equipment and selected park for pickup or delivery. The obtained confusion matrix resulted from proposed approach based on NB for automated planner in steel industry show its predicted decision closed to decisions of human planner (Figure 6).

Figure 5. The planning precise of developed approach based on NB for decisions in selection of equipment.

Figure 6. The planning precise of developed approach based on NB for decisions in steel industry.
Using bayesian networks to consider the dependency among planning parameters, we present an automated planner of pickup and delivery in inventory. The first phase of proposed approach is checking of circumstances to learn structure. We use chi-square goodness for normal test. Identifying the initial order of nodes is using of Maximum Weight Spanning Tree algorithm (MWST) that it is a popular to extract subset of the edges that connects all the vertices together and K2 algorithm for structure learning of a bayesian network. Then, it is used Maximum Likelihood Estimation (MLE) algorithm to learn the bayesian network parameters. In order to evaluate the efficiency of the proposed approach, we apply it to real data in the steel industry. The experiments show the proposed approach results decisions that are similar to human planner.
Although the proposed approach has alleviated some of issues in inventory planning of steel industry, but there are some of cases, which is better to improve them. In future studies, we plan to extend our proposed approach by taking into account pile size.
Journal of Steel Structures & Construction received 583 citations as per Google Scholar report