Youssouf Ismail Cherifi and Tarek Bouamer
Institute of Electrical & Electronic Engineering, Algeria
Scientific Tracks Abstracts: Adv Robot Autom
Speaker recognition is the task of identifying or verifying the speaker based on speaker specific features such as MFCC, IMFCC, LPC, LPCC and so on. The problem is that each feature contains a certain level of information that no other set of features can provide. However, all this information can be split into two categories-features that model the speech production system and features that are used to model the human way of hearing. The objective of this paper is to use two set of features and deep learning in order to enhance the accuracy of speaker recognition task. The two set of features are selected such that they represent both the speech production and hearing systems. This system can also be used to extract deep features that can be used to replace the classical speaker specific features.
Youssouf Ismail Cherifi is currently pursuing his PhD at IGEE (ex-Inelec). He has completed his Master’s degree in Computer Engineering and previously worked on the implementation and control of a biped robot using static walk and Arduino.
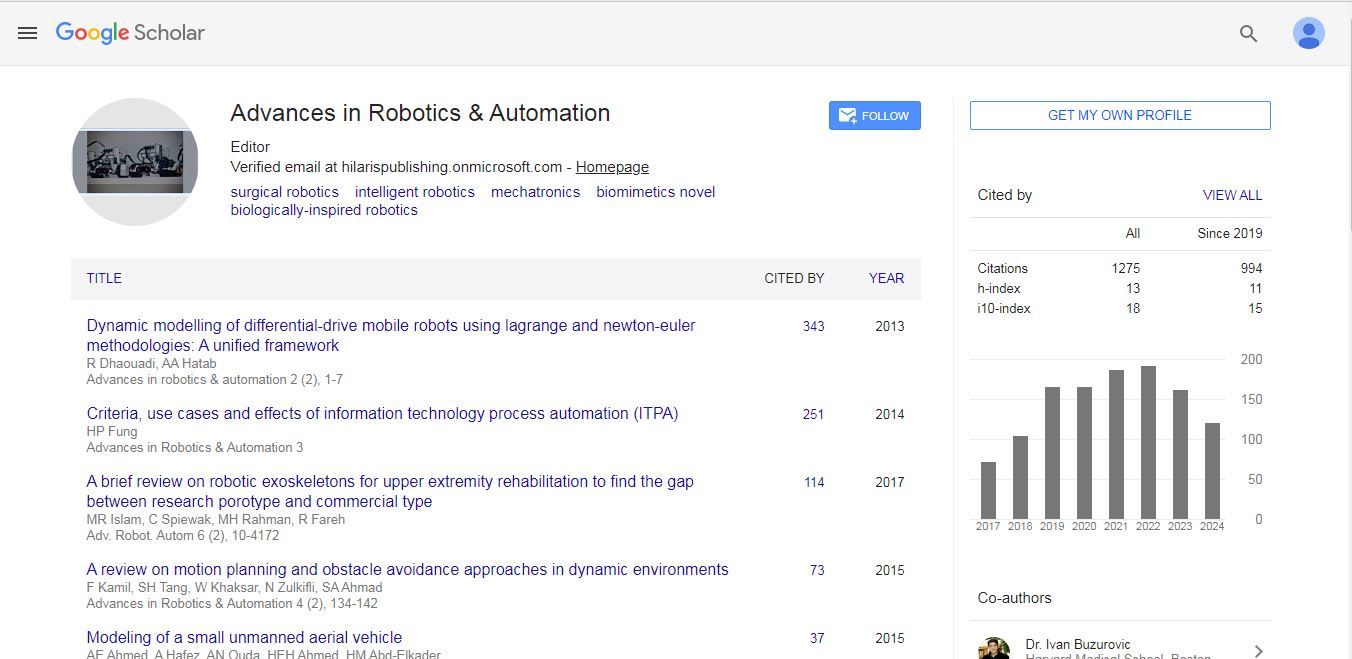
Advances in Robotics & Automation received 1275 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 