Karunkar Singamreddy
Digitalist Group, USA
Posters & Accepted Abstracts: Adv Robot Autom
Detecting the image of an object is difficult. Looking at an image and having to describe the contents of the image gives a rich set of opportunities to humans to describe it in multiple ways. Not just the names of the objects in the image, but the relative position and proportion of the images could be explained in different ways. In addition, the task gets even diverse when one has to explain the details of interaction between objects in the image. The initial solution of hard coded visual concepts and sentence templates would not work and also are restrictive. The modern-day captioning solutions include Multimodal RNN, pre-trained CNN models on large image datasets and the required image datasets. I will discuss the fundamentals of neural networks, talk about text processing using RNNs, explain the current state-of-the-art in pre-training CNN models on large image datasets and share the details of how to create a complex model to train and infer on images and text. The agenda of this presentation includes: Intro to Neural Networks, RNNs, LSTMs, Encoder-Decoders; Intro to CNN; Preferred open-sourced frameworks for image processing; ImageNet challenges and the progress made; Pre-trained models on large image datasets; Language Models; Multimodal RNNs; Latest solutions for image based Question-Answers (for example, how many people are in this image?) and Hands on solutions to implement the building blocks for Image Captioning. The attendees will understand the concepts, discuss the building blocks of NLP and Image Processing Models and learn the practical approaches to build an Image Captioning model. skreddy99@gmail.com
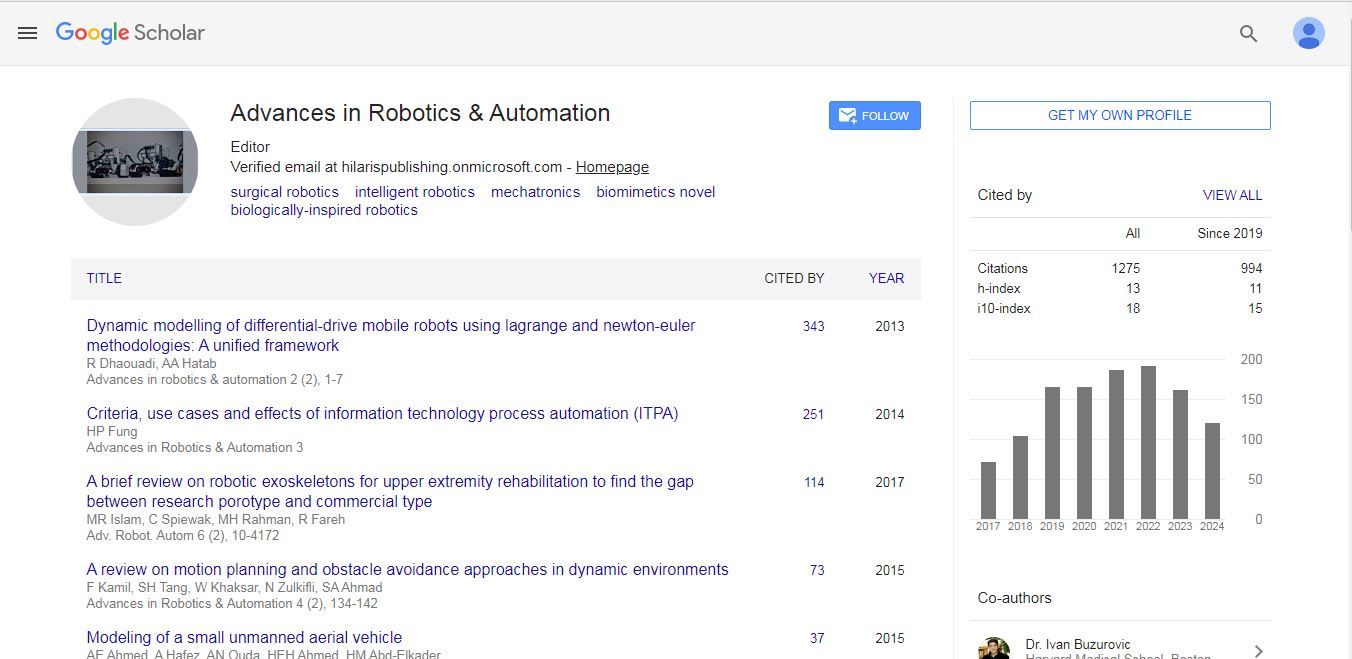
Advances in Robotics & Automation received 1275 citations as per Google Scholar report

 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 