Editorial
Pages: 1 - 3DOI:
Research
Pages: 1 - 7Anjali Wadhwani and Varun Khanna
DOI:
Currently, most reverse vaccinology studies aim to identify novel proteins with signature motifs commonly found in surface exposed proteins. In the current manuscript, our objective was to computationally identify conserved, antigenic, classically or non-classically secreted proteins in pathogenic strains of Streptococcus pneumoniae. The pathogenic strains used in our analysis were TIGR4, D39, CGSP14, 19A-6, JJA, 70585, AP200, 6706B and TCH8431. PSORTb 3.0.2 was used to infer subcellular locations while SecretomeP 2.0 server was run to predict non-classically secreted proteins. Virulence was predicted using MP3 and VirulentPred webservers. A systematic workflow designed for reverse vaccinology identified 83 (45 classically secreted and 38 non-classically secreted) potential virulence factors. However, many proteins were uncharacterized. Therefore, InterProScan was run for functional annotation. Proteins failing to be annotated were filtered out leaving a set of 24 proteins (9 classically secreted and 15 non-classically secreted) as our final prediction for potential vaccine candidates. Nevertheless, predicted proteins needs to be validated in biological assays before their use as vaccines.
Research Article
Pages: 1 - 7DOI:
Large number of autonomous robot solutions exists for various missions and domains. These robots are sufficient for the missions they are built for. At the same time each of them has limited functional and physical capabilities. Multi agent systems can be used to remove these limits. However it is true only in case when the system ensures effective interaction among the robots i.e. enables their social behavior. Usually it is hard to implement such capabilities directly into robots due to functional and physical limitations and heterogeneity of the team. One of possible solutions is to implement a behavior sensors management for the robots. It should collect events, allocate subtasks to specific robots and monitor the execution of the assigned tasks. In order to avoid inherent drawback of fully centralized systems a significant level of autonomy has to be preserved. Intelligent agents fulfill these requirements. Therefore we propose a multi-agent system’s architecture for safe road application with GPS tool. It can be used to control the car speed and to adjust it in case of danger.
Research Article
Pages: 1 - 11Elhassan AT, Aljourf M, Al-Mohanna F and Shoukri M
DOI:
The problem of classifying subjects into disease categories is of common occurrence in medical research. Machine learning tools such as Artificial Neural Network (ANN), Support Vector Machine (SVM) and Logistic Regression (LR) and Fisher’s Linear Discriminant Analysis (LDA) are widely used in the areas of prediction and classification. The main objective of these competing classification strategies is to predict a dichotomous outcome (e.g. disease/healthy) based on several features. Like any of the well-known statistical inferential models; machine learning tools are faced with a problem known as “class imbalance”. A data set is imbalanced if the classification categories are not approximately equally represented. When learning from highly imbalanced data, most classifiers are affected by the majority class leading to an increase in the false negative rate. Increased interests in applying machine learning techniques to "real-world" problems, whose data are characterized by severe imbalance, have emerged as can be seen in numerous publications in medicine and biology. Predictive accuracy, a popular choice for evaluating performance of a classifier, might not be appropriate when the data is imbalanced and/or when the costs of different errors vary markedly. In this paper, we use the T-Link algorithm in the preprocessing phase as a method of data cleaning in order to remove noise. We combine T-Link with other sampling method such as RUS, ROS and Synthetic Minority Technique (SMOTE) in order to maintain a balanced class distribution. Classification was then utilized using several ML algorithms such as ANN, RF and LR. Classifiers performance was evaluated using several performance measures deemed more appropriate for classifying data with sever imbalance. These methods are applied to arterial blood pressures data and Ecoli2 data set. Using TLink in combination with RUS and SMOTE demonstrated a superior performance compared to resampling techniques such among different classification algorithms such as SVM, ANN, RF and LR.
Research
Pages: 1 - 10Valarezo UA, Pérez-Amaral T and Gijón C
DOI:
What if we ask ourselves about what is the operating system and the physical infrastructure behind tools and services people use almost every day, and what is making possible that well-known companies like Google, Yahoo, Bing, Amazon, Facebook, Twitter, LinkedIn, Netflix, etc. are able to deliver such high quality services like they do. What makes possible the increasing accuracy of Google Translator, the appropriate recommendations of Amazon, the contact suggestions of LinkedIn, the Netflix’s hit House of Cards. Of course we have to imagine something much more bigger than the operating system we use at home or within a small company to drive our day to day work.
Though the beginnings of Big Data as hype term are not far away in time, it seems lengthy if we consider how it is evolving from just a technological phenomenon to a new discipline, which comprises many areas of knowledge, challenging not just the directly related ones as computing science, statistics, data science but others less obvious as sociology, ethics, philosophy, etc.
Three goals have driven this work: build our own definition and understanding of Big Data; get experience at using available tools based on related technologies and obtaining an approach about how interested is Spain in dealing with the new challenges Big Data represents.
Research
Pages: 1 - 10DOI:
Legacy (and current) medical datasets are rich source of information and knowledge. However, the use of most legacy medical datasets is beset with problems. One of the most often faced is the problem of missing data, often due to oversights in data capture or data entry procedures. Algorithms commonly used in the analysis of data often depend on a complete data set. Missing value imputation offers a solution to this problem. This may result in the generation of synthetic data, with artificially induced missing values, but simply removing the incomplete data records often produces the best classifier results. With legacy data, simply removing the records from the original datasets can significantly reduce the data volume and often affect the class balance of the dataset. A suitable method for missing value imputation is very much needed to produce good quality datasets for better analysing data resulting from clinical trials. This paper proposes a framework for missing value imputation using stratified machine learning methods. We explore machine learning technique to predict missing value for incomplete clinical (cardiovascular) data, with experiments comparing this with other standard methods. Two machine learning (classifier) algorithms, fuzzy unordered rule induction algorithm and decision tree, plus other machine learning algorithms (for comparison purposes) are used to train on complete data and subsequently predict missing values for incomplete data. The complete datasets are classified using decision tree, neural network, K-NN and K-Mean clustering. The classification performances are evaluated using sensitivity, specificity, accuracy, positive predictive value and negative predictive value. The results show that final classifier performance can be significantly improved for all class labels when stratification was used with fuzzy unordered rule induction algorithm to predict missing attribute values.
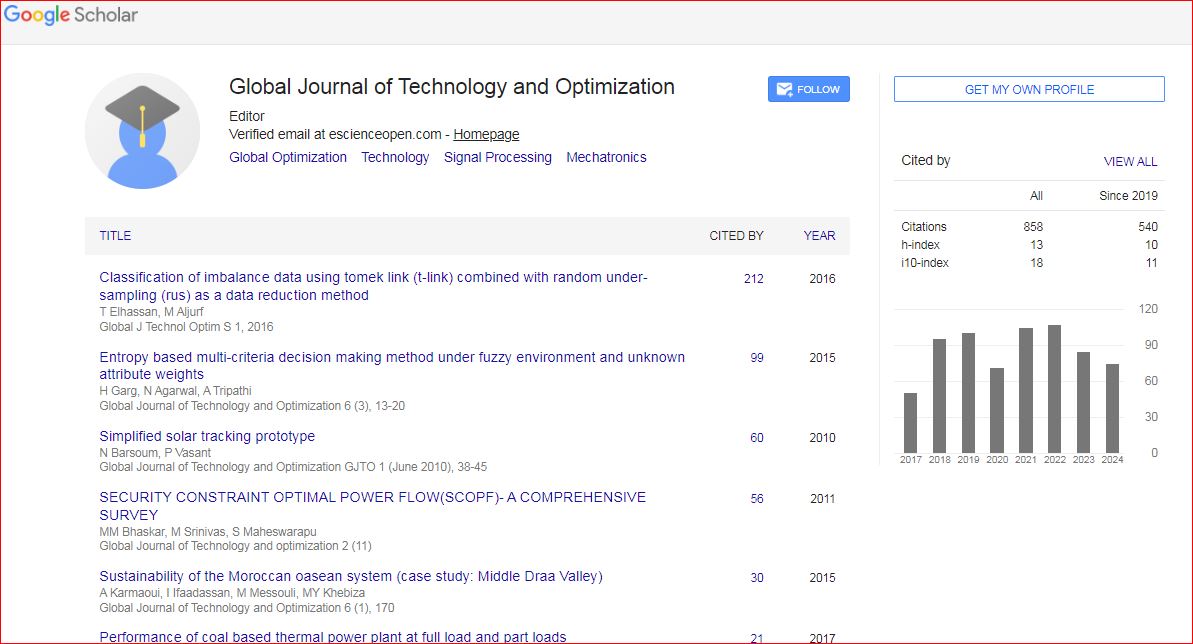
Global Journal of Technology and Optimization received 847 citations as per Google Scholar report
 Spanish
Spanish  Chinese
Chinese  Russian
Russian  German
German  French
French  Japanese
Japanese  Portuguese
Portuguese  Hindi
Hindi 